可观测性
Istio 为网格内所有的服务通信生成详细的遥测数据。这种遥测技术提供了服务行为的可观测性, 使运维人员能够排查故障、维护和优化应用程序,而不会给服务的开发人员带来任何额外的负担。 通过 Istio,运维人员可以全面了解到受监控的服务如何与其他服务以及 Istio 组件进行交互。
Istio 生成以下类型的遥测数据,以提供对整个服务网格的可观测性:
- 指标。Istio 基于 4 个监控的黄金标识(延迟、流量、错误、饱和)生成了一系列服务指标。 Istio 还为网格控制平面提供了更详细的指标。 除此以外还提供了一组默认的基于这些指标的网格监控仪表板。
- 分布式追踪。Istio 为每个服务生成分布式追踪 span, 运维人员可以理解网格内服务的依赖和调用流程。
- 访问日志。当流量流入网格中的服务时, Istio 可以生成每个请求的完整记录,包括源和目标的元数据。 此信息使运维人员能够将服务行为的审查控制到单个工作负载实例的级别。
指标
指标(Metric)提供了一种以聚合的方式监控和理解行为的方法。
为了监控服务行为,Istio 为服务网格中所有出入网格, 以及网格内部的服务流量都生成了指标。这些指标提供了关于行为的信息, 例如总流量数、错误率和请求响应时间。
除了监控网格中服务的行为外,监控网格本身的行为也很重要。 Istio 组件可以导出自身内部行为的指标, 以提供对网格控制平面的功能和健康情况的洞察能力。
代理级别指标
Istio 指标收集从 Sidecar 代理(Envoy)开始。 每个代理为通过它的所有流量(入站和出站)生成一组丰富的指标。 代理还提供关于它本身管理功能的详细统计信息,包括配置信息和健康信息。
Envoy 生成的指标提供了资源(例如监听器和集群)粒度上的网格监控。 因此,为了监控 Envoy 指标,需要了解网格服务和 Envoy 资源之间的连接。
Istio 允许运维人员在每个工作负载实例上选择生成和收集哪个 Envoy 指标。 默认情况下,Istio 只支持 Envoy 生成的统计数据的一小部分, 以避免依赖过多的后端服务,还可以减少与指标收集相关的 CPU 开销。 然而,运维人员可以在需要时轻松地扩展收集到的代理指标集。 这支持有针对性地调试网络行为,同时降低了跨网格监控的总体成本。
Envoy 文档包括了 Envoy 统计信息收集的详细说明。 Envoy 统计里的操作手册提供了有关控制代理级别指标生成的更多信息。
代理级别指标的例子:
envoy_cluster_internal_upstream_rq{response_code_class="2xx",cluster_name="xds-grpc"} 7163
envoy_cluster_upstream_rq_completed{cluster_name="xds-grpc"} 7164
envoy_cluster_ssl_connection_error{cluster_name="xds-grpc"} 0
envoy_cluster_lb_subsets_removed{cluster_name="xds-grpc"} 0
envoy_cluster_internal_upstream_rq{response_code="503",cluster_name="xds-grpc"} 1服务级别指标
除了代理级别指标之外,Istio 还提供了一组用于监控服务通信的面向服务的指标。 这些指标涵盖了四个基本的服务监控需求:延迟、流量、错误和饱和情况。 Istio 带有一组默认的仪表板, 用于监控基于这些指标的服务行为。
默认情况下,标准 Istio 指标会导出到 Prometheus。
服务级别指标的使用完全是可选的。运维人员可以选择关闭指标的生成和收集来满足自身需要。
服务级别指标的例子:
istio_requests_total{
connection_security_policy="mutual_tls",
destination_app="details",
destination_canonical_service="details",
destination_canonical_revision="v1",
destination_principal="cluster.local/ns/default/sa/default",
destination_service="details.default.svc.cluster.local",
destination_service_name="details",
destination_service_namespace="default",
destination_version="v1",
destination_workload="details-v1",
destination_workload_namespace="default",
reporter="destination",
request_protocol="http",
response_code="200",
response_flags="-",
source_app="productpage",
source_canonical_service="productpage",
source_canonical_revision="v1",
source_principal="cluster.local/ns/default/sa/default",
source_version="v1",
source_workload="productpage-v1",
source_workload_namespace="default"
} 214控制平面指标
Istio 控制平面还提供了一组自我监控指标。这些指标容许监控 Istio 自己的行为(这与网格内的服务有所不同)。
有关这些被维护指标的更多信息,请查看参考文档。
分布式追踪
分布式追踪通过监控流经网格的单个请求,提供了一种监控和理解行为的方法。 追踪使网格的运维人员能够理解服务的依赖关系以及在服务网格中的延迟源。
Istio 支持通过 Envoy 代理进行分布式追踪。代理自动为其应用程序生成追踪 span, 只需要应用程序转发适当的请求上下文即可。
Istio 支持很多追踪系统,包括 Zipkin、 Jaeger, 以及许多支持 OpenTelemetry 的工具和服务。 操作员控制链路生成的采样率(即每个请求生成链路数据的速率)。 这允许操作员控制为其网格生成的链路追踪数据的数量和速率。
更多关于 Istio 分布式追踪的信息可以在分布式追踪 FAQ 中找到。
Istio 为单个请求生成的分布式追踪示例:
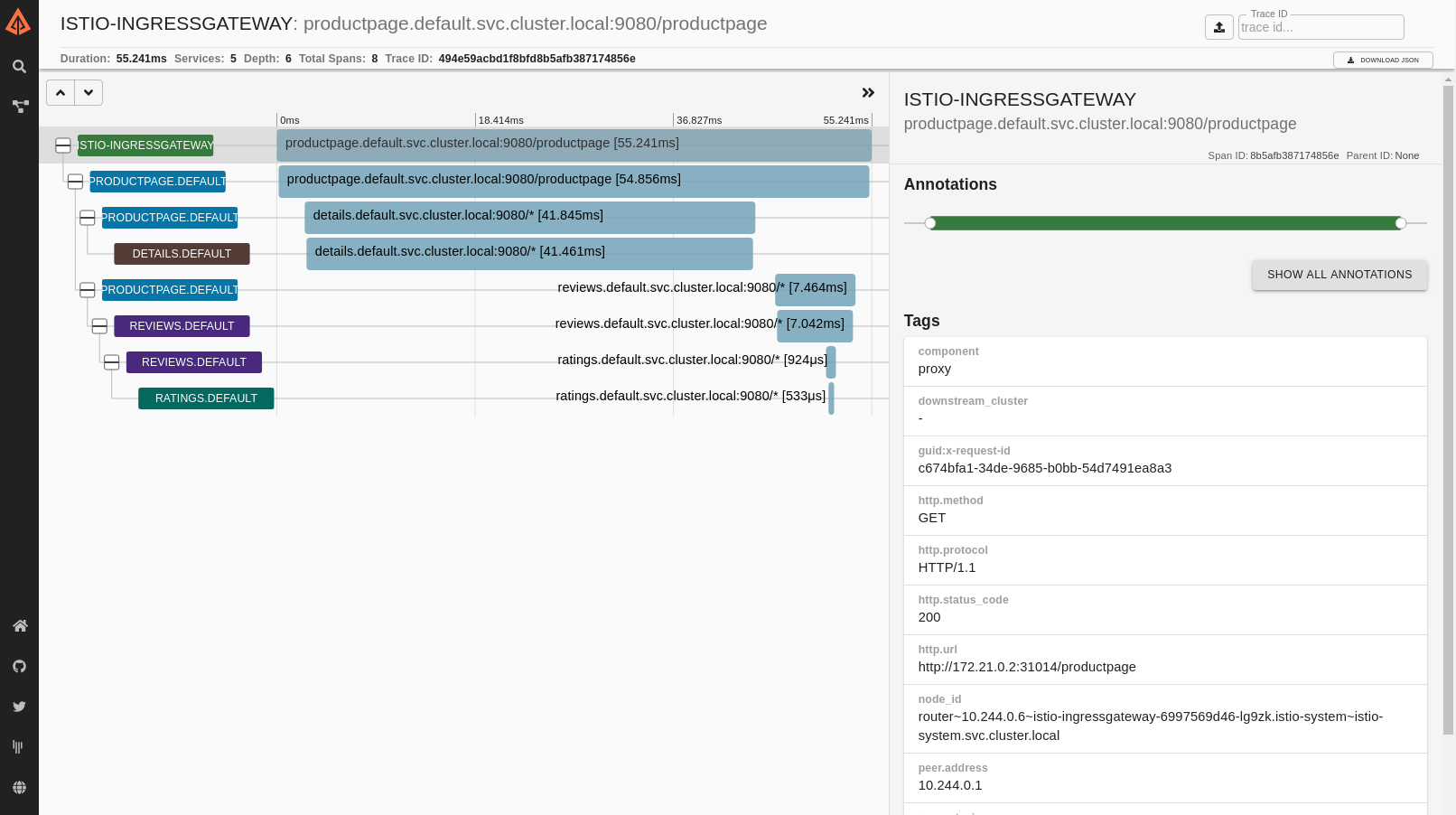
访问日志
访问日志提供了一种从单个工作负载实例的角度监控和理解行为的方法。
Istio 能够以一组可配置的格式为服务流量生成访问日志, 使操作员可以完全控制日志记录的方式、内容、时间和地点。 有关更多信息,请参阅获取 Envoy 的访问日志。
Istio 访问日志示例:
[2019-03-06T09:31:27.360Z] "GET /status/418 HTTP/1.1" 418 - "-" 0 135 5 2 "-" "curl/7.60.0" "d209e46f-9ed5-9b61-bbdd-43e22662702a" "httpbin:8000" "127.0.0.1:80" inbound|8000|http|httpbin.default.svc.cluster.local - 172.30.146.73:80 172.30.146.82:38618 outbound_.8000_._.httpbin.default.svc.cluster.local