Merbridge - Accelerate your mesh with eBPF
Replacing iptables rules with eBPF allows transporting data directly from inbound sockets to outbound sockets, shortening the datapath between sidecars and services.
The secret of Istio’s abilities in traffic management, security, observability and policy is all in the Envoy proxy. Istio uses Envoy as the “sidecar” to intercept service traffic, with the kernel’s netfilter packet filter functionality configured by iptables.
There are shortcomings in using iptables to perform this interception. Since netfilter is a highly versatile tool for filtering packets, several routing rules and data filtering processes are applied before reaching the destination socket. For example, from the network layer to the transport layer, netfilter will be used for processing for several times with the rules predefined, like pre_routing, post_routing and etc. When the packet becomes a TCP packet or UDP packet, and is forwarded to user space, some additional steps like packet validation, protocol policy processing and destination socket searching will be performed. When a sidecar is configured to intercept traffic, the original data path can become very long, since duplicated steps are performed several times.
Over the past two years, eBPF has become a trending technology, and many projects based on eBPF have been released to the community. Tools like Cilium and Pixie show great use cases for eBPF in observability and network packet processing. With eBPF’s sockops and redir capabilities, data packets can be processed efficiently by directly being transported from an inbound socket to an outbound socket. In an Istio mesh, it is possible to use eBPF to replace iptables rules, and accelerate the data plane by shortening the data path.
We have created an open source project called Merbridge, and by applying the following command to your Istio-managed cluster, you can use eBPF to achieve such network acceleration.
$ kubectl apply -f https://raw.githubusercontent.com/merbridge/merbridge/main/deploy/all-in-one.yaml
With Merbridge, the packet datapath can be shortened directly from one socket to another destination socket, and here’s how it works.
Using eBPF sockops for performance optimization
Network connection is essentially socket communication. eBPF provides a function bpf_msg_redirect_hash, to directly forward the packets sent by the application in the inbound socket to the outbound socket. By entering the function mentioned before, developers can perform any logic to decide the packet destination. According to this characteristic, the datapath of packets can noticeably be optimized in the kernel.
The sock_map is the crucial piece in recording information for packet forwarding. When a packet arrives, an existing socket is selected from the sock_map to forward the packet to. As a result, we need to save all the socket information for packets to make the transportation process function properly. When there are new socket operations — like a new socket being created — the sock_ops function is executed. The socket metadata is obtained and stored in the sock_map to be used when processing packets. The common key type in the sock_map is a “quadruple” of source and destination addresses and ports. With the key and the rules stored in the map, the destination socket will be found when a new packet arrives.
The Merbridge approach
Let’s introduce the detailed design and implementation principles of Merbridge step by step, with a real scenario.
Istio sidecar traffic interception based on iptables
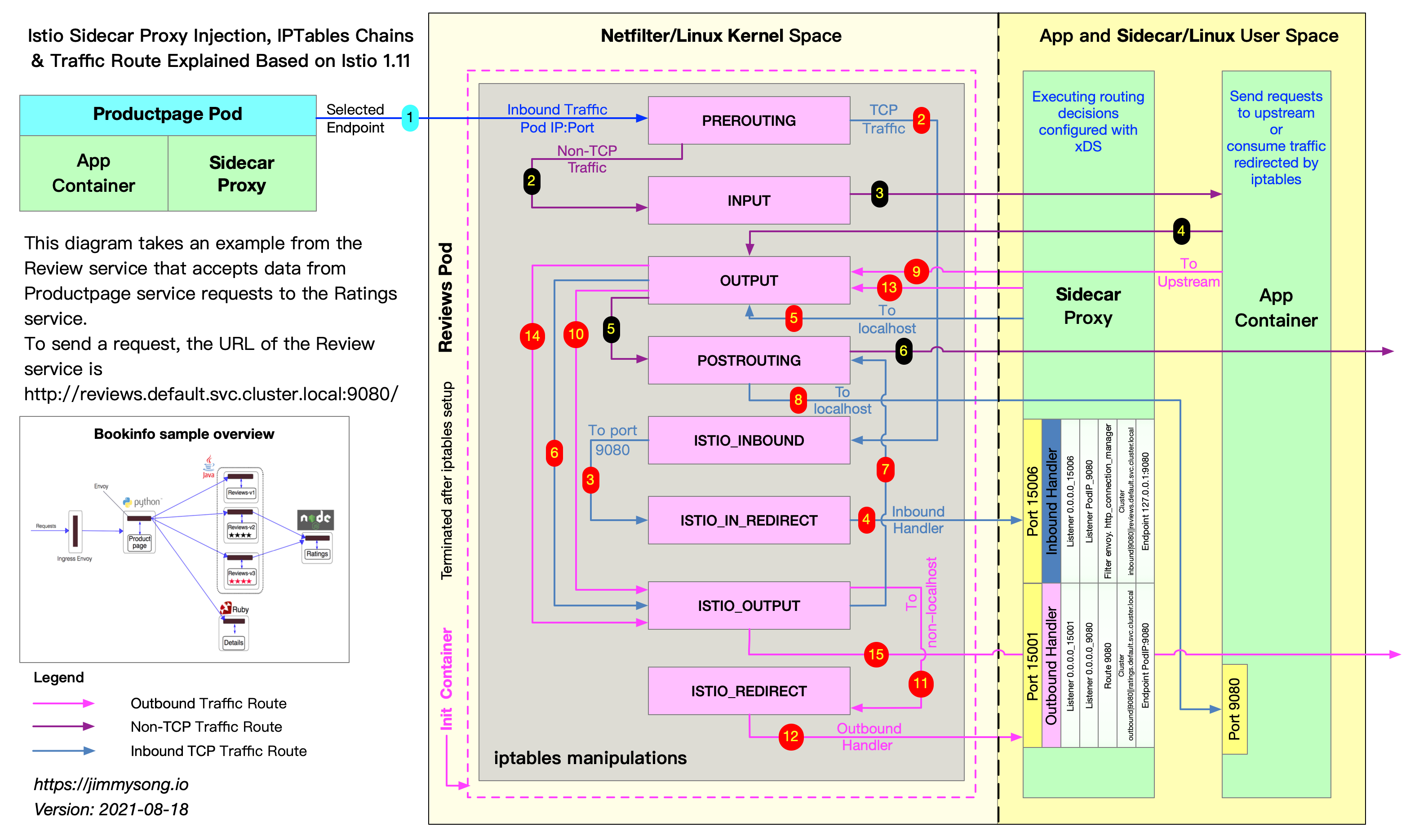
When external traffic hits your application’s ports, it will be intercepted by a PREROUTING rule in iptables, forwarded to port 15006 of the sidecar container, and handed over to Envoy for processing. This is shown as steps 1-4 in the red path in the above diagram.
Envoy processes the traffic using the policies issued by the Istio control plane. If allowed, the traffic will be sent to the actual container port of the application container.
When the application tries to access other services, it will be intercepted by an OUTPUT rule in iptables, and then be forwarded to port 15001 of the sidecar container, where Envoy is listening. This is steps 9-12 on the red path, similar to inbound traffic processing.
Traffic to the application port needs to be forwarded to the sidecar, then sent to the container port from the sidecar port, which is overhead. Moreover, iptables’ versatility determines that its performance is not always ideal because it inevitably adds delays to the whole datapath with different filtering rules applied. Although iptables is the common way to do packet filtering, in the Envoy proxy case, the longer datapath amplifies the bottleneck of packet filtering process in the kernel.
If we use sockops to directly connect the sidecar’s socket to the application’s socket, the traffic will not need to go through iptables rules, and thus performance can be improved.
Processing outbound traffic
As mentioned above, we would like to use eBPF’s sockops to bypass iptables to accelerate network requests. At the same time, we also do not want to modify any parts of Istio, to make Merbridge fully adaptive to the community version. As a result, we need to simulate what iptables does in eBPF.
Traffic redirection in iptables utilizes its DNAT function. When trying to simulate the capabilities of iptables using eBPF, there are two main things we need to do:
- Modify the destination address, when the connection is initiated, so that traffic can be sent to the new interface.
- Enable Envoy to identify the original destination address, to be able to identify the traffic.
For the first part, we can use eBPF’s connect program to process it, by modifying user_ip and user_port.
For the second part, we need to understand the concept of ORIGINAL_DST which belongs to the netfilter module in the kernel.
When an application (including Envoy) receives a connection, it will call the get_sockopt function to obtain ORIGINAL_DST. If going through the iptables DNAT process, iptables will set this parameter, with the “original IP + port” value, to the current socket. Thus, the application can get the original destination address according to the connection.
We have to modify this call process through eBPF’s get_sockopts function. (bpf_setsockopt is not used here because this parameter does not currently support the optname of SO_ORIGINAL_DST).
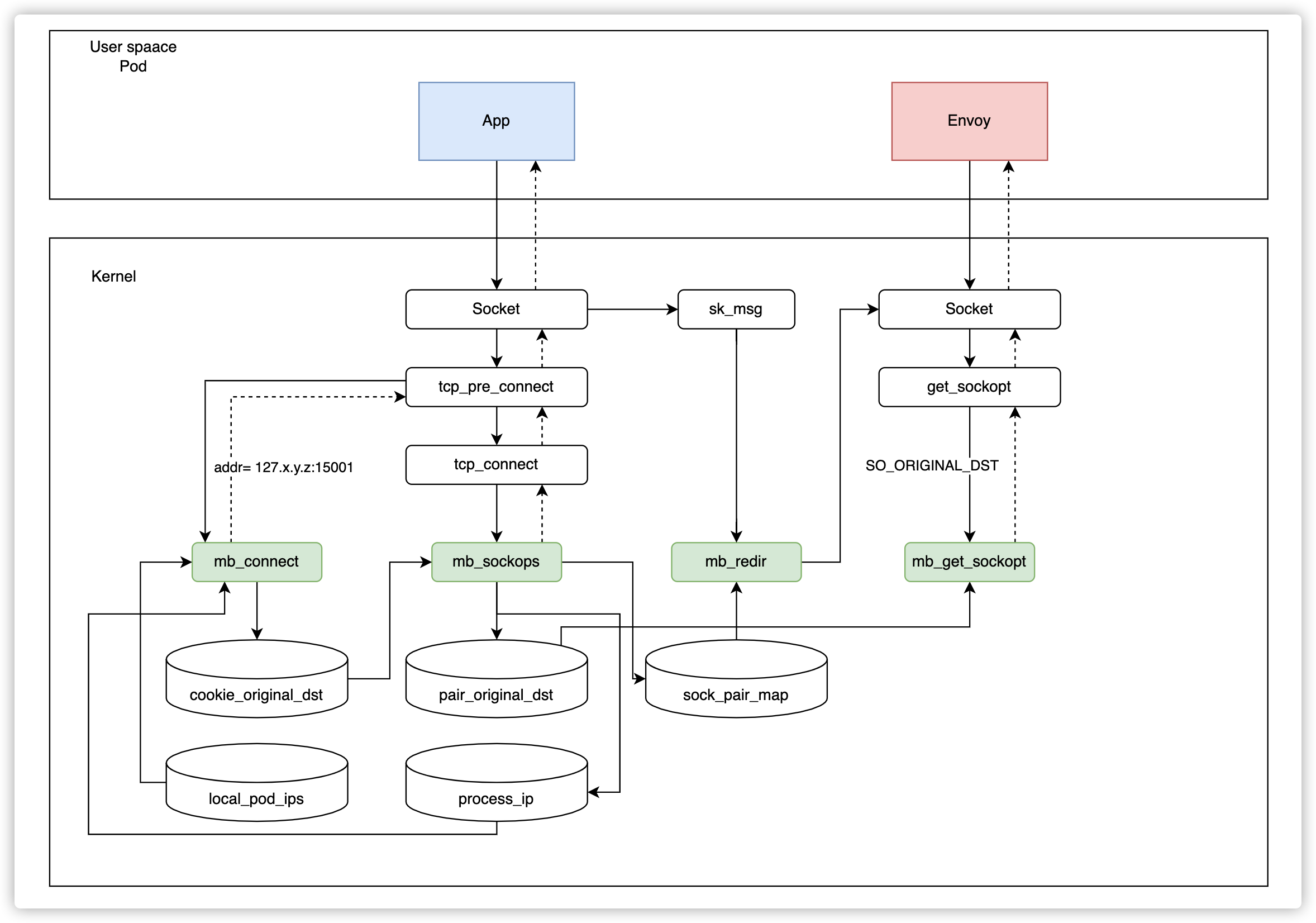
Referring to the figure below, when an application initiates a request, it will go through the following steps:
- When the application initiates a connection, the
connectprogram will modify the destination address to127.x.y.z:15001, and usecookie_original_dstto save the original destination address. - In the
sockopsprogram, the current socket information and the quadruple are saved insock_pair_map. At the same time, the same quadruple and its corresponding original destination address will be written topair_original_dest. (Cookie is not used here because it cannot be obtained in theget_sockoptprogram). - After Envoy receives the connection, it will call the
get_sockoptfunction to read the destination address of the current connection.get_sockoptwill extract and return the original destination address frompair_original_dst, according to the quadruple information. Thus, the connection is completely established. - In the data transport step, the
redirprogram will read the sock information fromsock_pair_mapaccording to the quadruple information, and then forward it directly throughbpf_msg_redirect_hashto speed up the request.
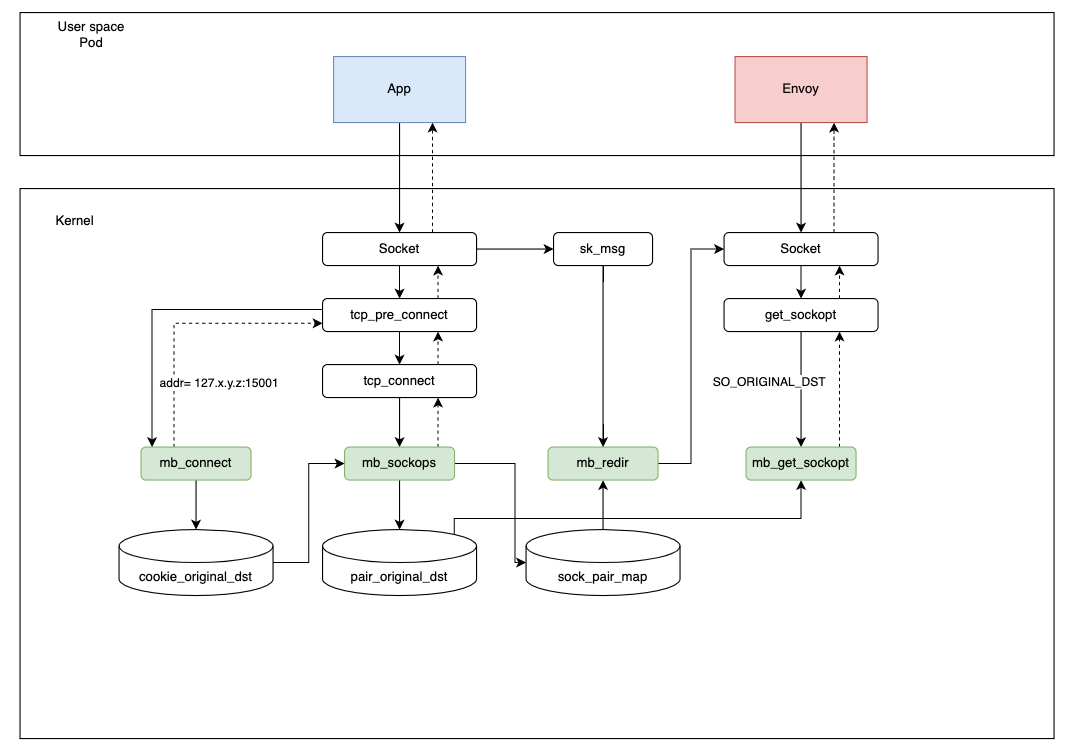
Why do we set the destination address to 127.x.y.z instead of 127.0.0.1? When different pods exist, there might be conflicting quadruples, and this gracefully avoids conflict. (Pods’ IPs are different, and they will not be in the conflicting condition at any time.)
Inbound traffic processing
The processing of inbound traffic is basically similar to outbound traffic, with the only difference: revising the port of the destination to 15006.
It should be noted that since eBPF cannot take effect in a specified namespace like iptables, the change will be global, which means that if we use a Pod that is not originally managed by Istio, or an external IP address, serious problems will be encountered — like the connection not being established at all.
As a result, we designed a tiny control plane (deployed as a DaemonSet), which watches all pods — similar to the kubelet watching pods on the node — to write the pod IP addresses that have been injected into the sidecar to the local_pod_ips map.
When processing inbound traffic, if the destination address is not in the map, we will not do anything to the traffic.
Otherwise, the steps are the same as for outbound traffic.
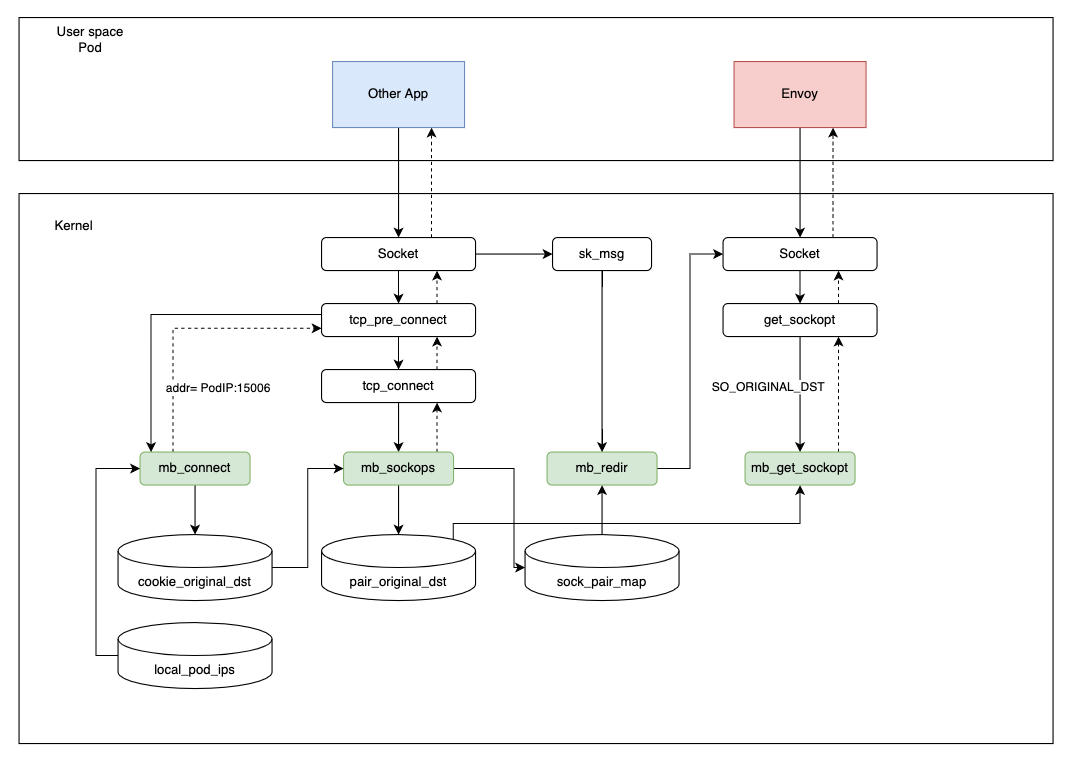
Same-node acceleration
Theoretically, acceleration between Envoy sidecars on the same node can be achieved directly through inbound traffic processing. However, Envoy will raise an error when accessing the application of the current pod in this scenario.
In Istio, Envoy accesses the application by using the current pod IP and port number. With the above scenario, we realized that the pod IP exists in the local_pod_ips map as well, and the traffic will be redirected to the pod IP on port 15006 again because it is the same address that the inbound traffic comes from. Redirecting to the same inbound address causes an infinite loop.
Here comes the question: are there any ways to get the IP address in the current namespace with eBPF? The answer is yes!
We have designed a feedback mechanism: When Envoy tries to establish the connection, we redirect it to port 15006. However, in the sockops step, we will determine if the source IP and the destination IP are the same. If yes, it means the wrong request is sent, and we will discard this connection in the sockops process. In the meantime, the current ProcessID and IP information will be written into the process_ip map, to allow eBPF to support correspondence between processes and IPs.
When the next request is sent, the same process need not be performed again. We will check directly from the process_ip map if the destination address is the same as the current IP address.
Connection relationship
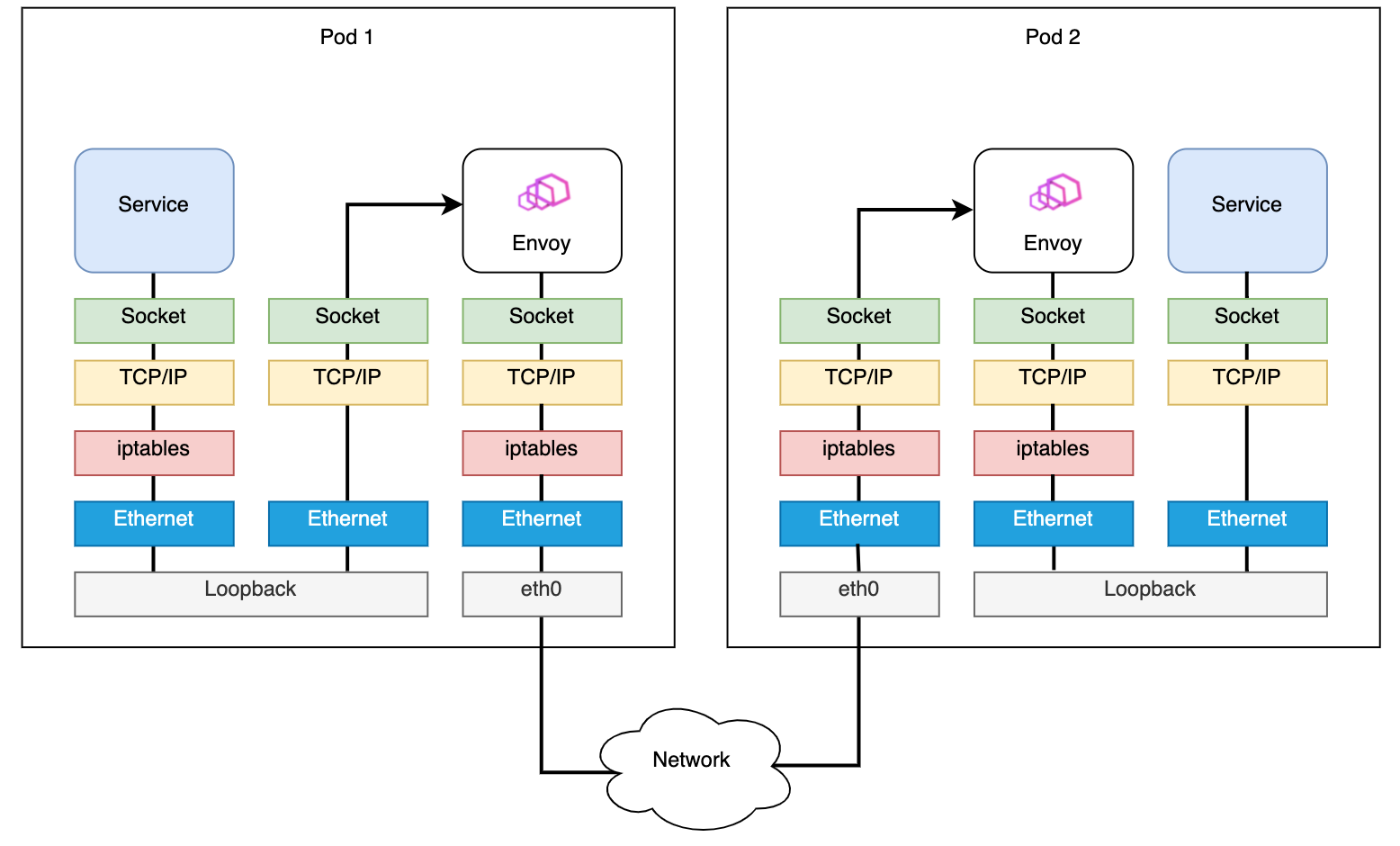
Before applying eBPF using Merbridge, the data path between pods is like:
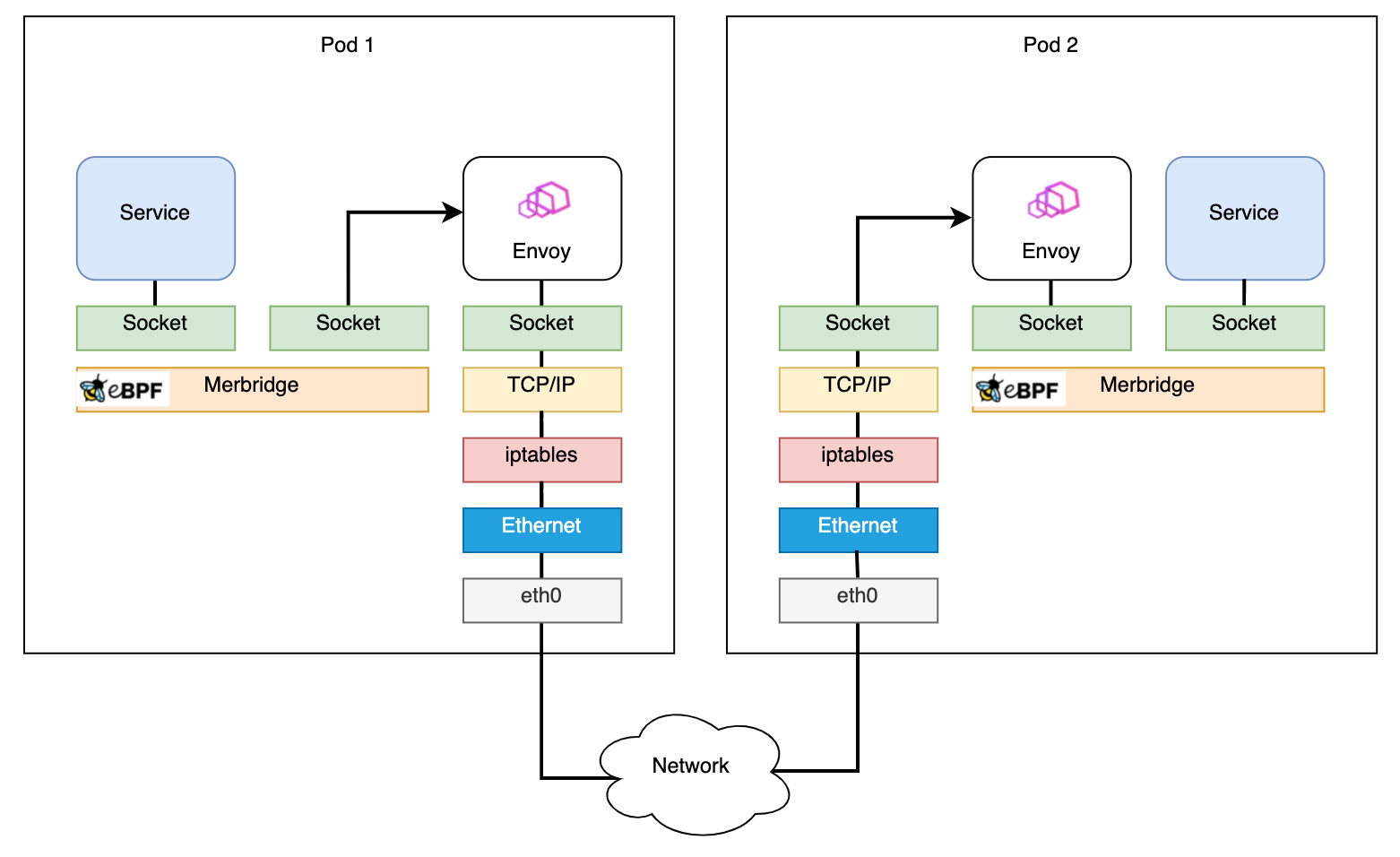
After applying Merbridge, the outbound traffic will skip many filter steps to improve the performance:
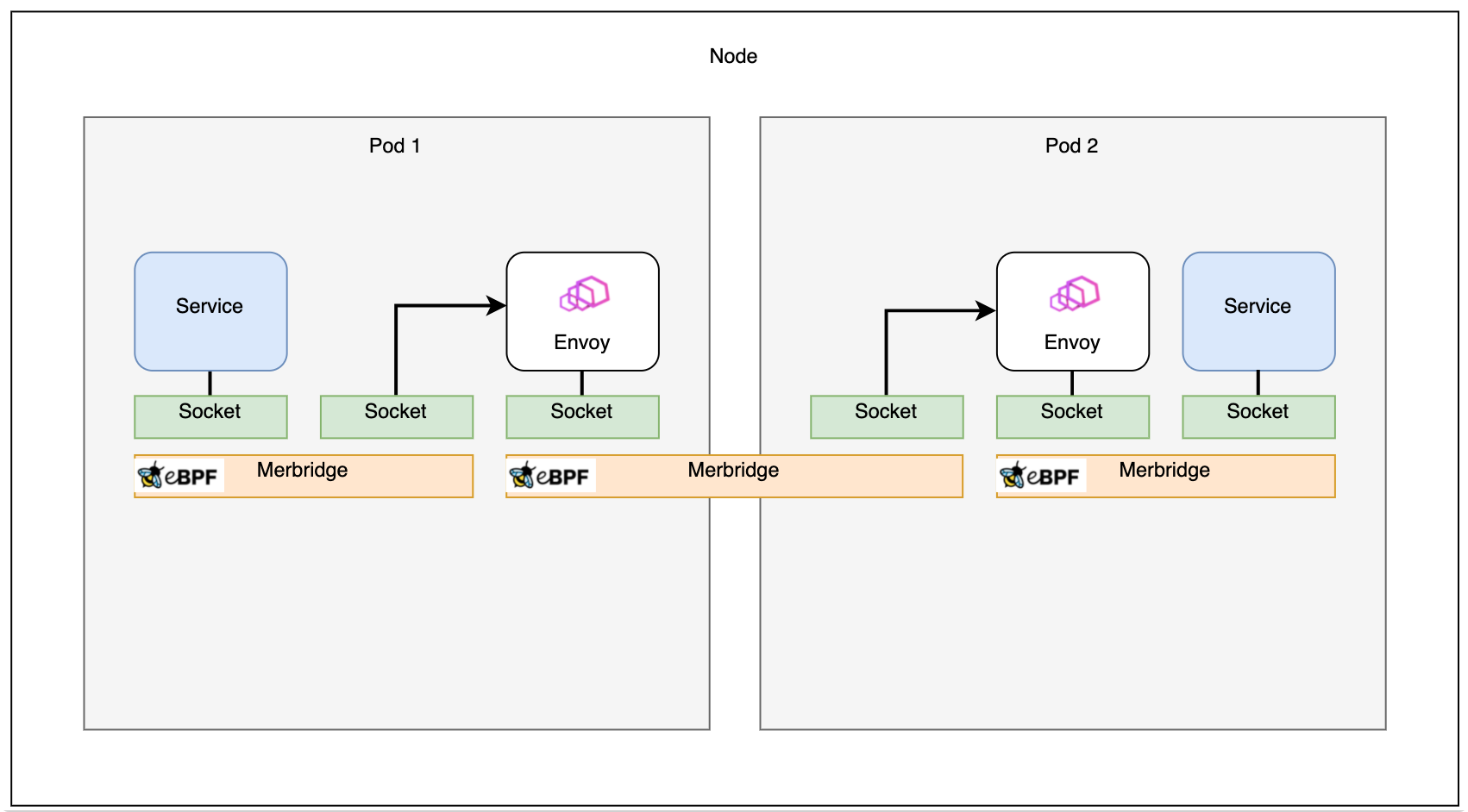
If two pods are on the same machine, the connection can even be faster:
Performance results
Let’s see the effect on overall latency using eBPF instead of iptables (lower is better):
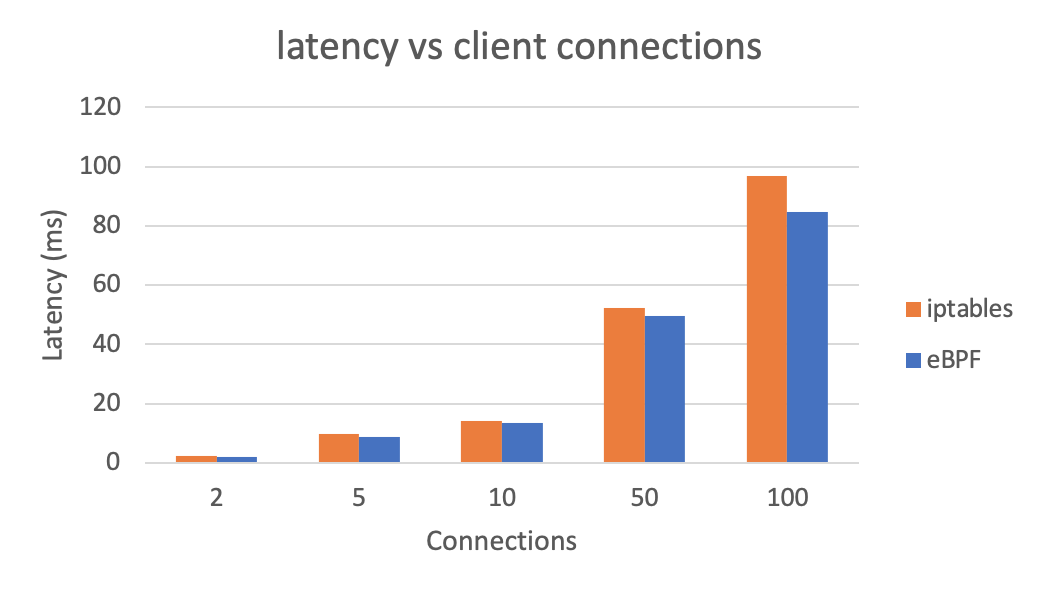
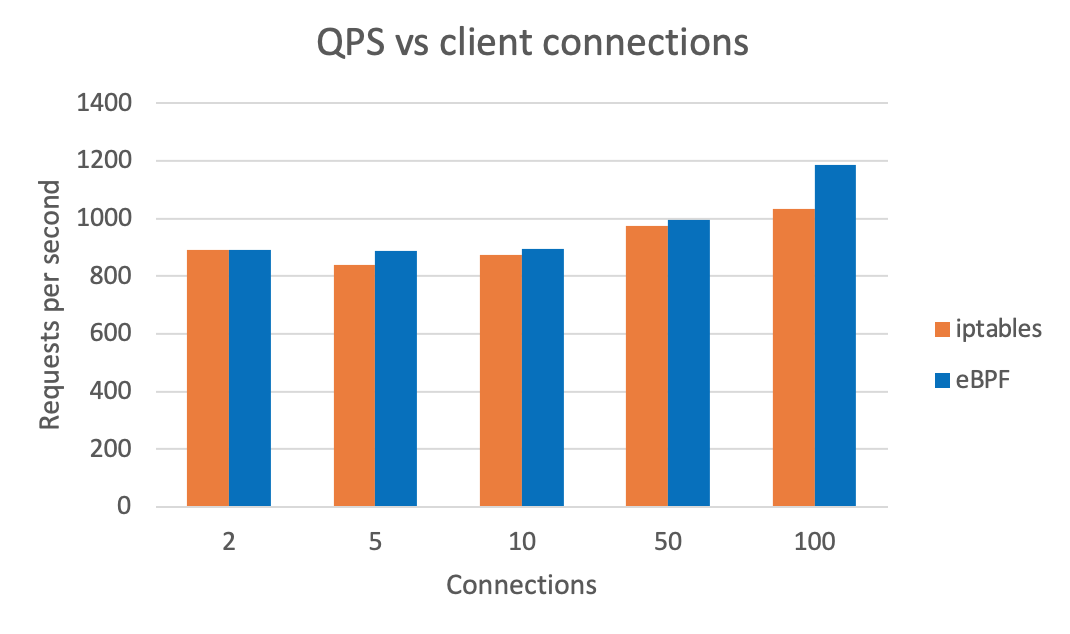
We can also see overall QPS after using eBPF (higher is better). Test results are generated with wrk.
Summary
We have introduced the core ideas of Merbridge in this post. By replacing iptables with eBPF, the data transportation process can be accelerated in a mesh scenario. At the same time, Istio will not be changed at all. This means if you do not want to use eBPF any more, just delete the DaemonSet, and the datapath will be reverted to the traditional iptables-based routing without any problems.
Merbridge is a completely independent open source project. It is still at an early stage, and we are looking forward to having more users and developers to get engaged. It would be greatly appreciated if you would try this new technology to accelerate your mesh, and provide us with some feedback!
See also
- Merbridge on GitHub
- Using eBPF instead of iptables to optimize the performance of service grid data plane by Liu Xu, Tencent
- Sidecar injection and transparent traffic hijacking process in Istio explained in detail by Jimmy Song, Tetrate
- Accelerate the Istio data plane with eBPF by Yizhou Xu, Intel
- Envoy’s Original Destination filter