Merbridge - 使用 eBPF 实现网络加速
用 eBPF 代替 iptables 规则可以将应用发出的包直接转发到对端的 socket,从而缩短 sidecar 和服务之间的数据路径。
Istio 在流量治理、加密、可观测性和策略方面的能力的秘密都在 Envoy 代理中。Istio 使用 Envoy 作为 “sidecar” 来拦截服务流量,并使用 iptables 配置的内核 netfilter 包过滤功能。
使用 iptables 来执行这种拦截有一些缺点。由于 netfilter 是一种高度通用的数据包过滤工具,在到达目的套接字之前,需要应用多种路由规则和数据过滤过程。例如,从网络层到传输层,netfilter 会使用预定义的规则进行多次处理,如 pre_routing,post_routing 等。当报文变成 TCP 或 UDP 报文,并被转发到用户空间时,还需要执行一些额外的步骤,如报文验证、协议策略处理和目的套接字搜索。当将 sidecar 配置为拦截流量时,原始数据路径可能会变得非常长,因为重复的步骤会执行多次。
在过去的两年中,eBPF 已经成为一种技术趋势,许多基于 eBPF 的项目已经发布到社区。像 Cilium 和 Pixie 这样的工具展示了 eBPF 在可观测性和网络数据包处理方面的大量用例。通过 eBPF 的 sockops 和 redir 功能,可以通过直接从入口 socket 传输到出口 socket 来有效地处理数据包。在 Istio 网格中,可以使用 eBPF 来替代 iptables 规则,并通过缩短数据路径来加速数据平面。
我们开源了 Merbridge 项目,只需要在 Istio 集群执行以下一条命令,即可直接使用 eBPF 代替 iptables 实现网络加速。
$ kubectl apply -f https://raw.githubusercontent.com/merbridge/merbridge/main/deploy/all-in-one.yaml使用 Merbridge,通讯可以直接从一个 socket 缩短到另一个目标 socket,下面是它的工作原理。
利用 eBPF 的 sockops 进行性能优化
网络连接本质上是 socket 之间的通讯,eBPF 提供了一个 bpf_msg_redirect_hash函数,用来将应用发出的包直接转发到对端的 socket,可以极大地加速包在内核中的处理流程。
这里 sock_map 是记录 socket 规则的关键部分,即根据当前的数据包信息,从 sock_map 中挑选一个存在的 socket 连接来转发请求。所以需要先在 sockops 的 hook 处或者其它地方,将 socket 信息保存到 sock_map,并提供一个规则 (一般为四元组) 根据 key 查找到 socket。
Merbridge 的实现原理
让我们通过一个真实的场景,一步一步地介绍 Merbridge 的详细设计和实现原则。
基于 iptables 的 Istio sidecar 流量拦截 Istio
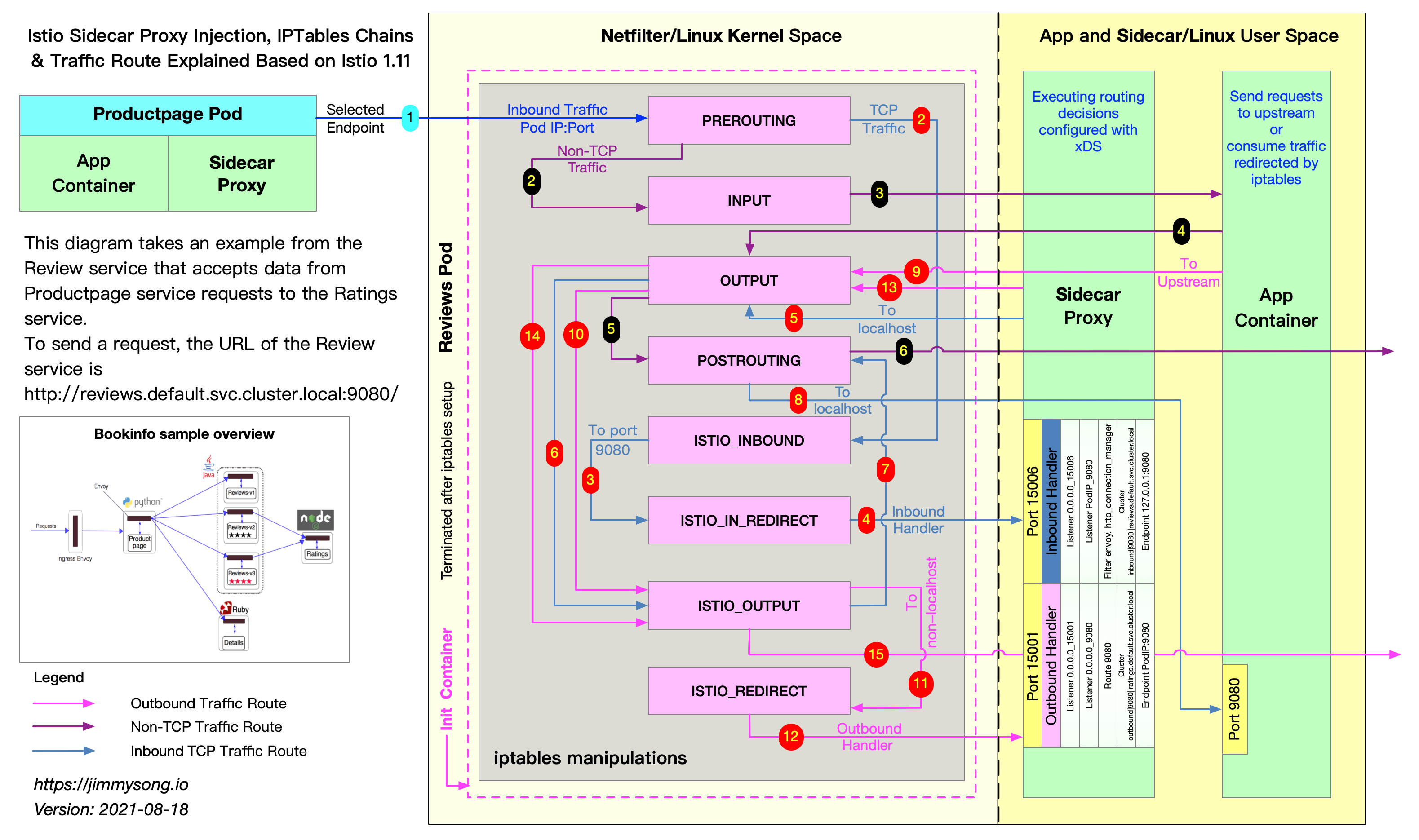
当外部流量访问应用的端口时,会在 iptables 中被 PREROUTING 拦截,最后转发到 Sidecar 容器的 15006 端口,然后交给 Envoy 来进行处理 (图中 1-4 的红色路径)。
Envoy 使用 Istio 控制平面下发的策略对流量进行处理。如果允许,流量将被发送到应用程序容器的实际容器端口。
当应用想要访问其它服务时,会在 iptables 中被 OUTPUT 拦截,然后转发给 Sidecar 容器的 15001 端口由 Envoy 监听 (图中 9-12 的红色路径),与入口流量的处理差不多。
原本流量可以直接到应用端口,但是通过 iptables 转发到 Sidecar,然后又让 Sidecar 发送给应用,这种方式无疑增加了开销。虽然 iptables 在很多情况下是通用的,但是它的通用性决定了它的性能并不总是很理想,因此它不可避免地会在不同的过滤规则下,给整个链路增加延迟。
如果使用 sockops 将 Sidecar 直接连接到应用的 Socket,就可以使流量不经过 iptables,加速处理流程,明显提高性能。
出口流量处理
如上所述,我们希望使用 eBPF 的 sockops 来绕过 iptables 以加速网络请求,同时希望能够完全适配社区版 Istio,所以需要先模拟 iptables 所做的操作。
iptables 本身使用 DNAT 功能做流量转发,想要用 eBPF 模拟 iptables 的能力,就需要使用 eBPF 实现类似 iptables DNAT 的能力。
- 修改连接发起时的目的地址,让流量能够发送到新的接口。
- 让 Envoy 能识别原始的目的地址,以能够识别流量。
对于第一点,可以使用 eBPF 的 connect 程序修改 user_ip 和 user_port 实现。
对于第二点,需要用到 ORIGINAL_DST 的概念,这在 Linux 内核中是 netfilter 模块专属的。
其原理为:应用程序 (包括 Envoy) 在收到连接之后调用 get_sockopts 函数,获取 ORIGINAL_DST。如果经过了 iptables 的 DNAT,那么 iptables 就会给当前的 socket 设置 ORIGINAL_DST 这个值,并把原有的 IP + 端口写入这个值,应用程序就可以根据连接拿到原有的目的地址。
那么我们就需要通过 eBPF 的 get_sockopt 函数来修改这个调用 (不用 bpf_setsockopt 的原因是目前这个参数并不支持 SO_ORIGINAL_DST 的 optname)。
参考下图,当一个应用程序发起一个请求时,它会经过以下步骤:
- 在应用向外发起连接时,
connect程序会将目标地址修改为127.x.y.z:15001,并用cookie_original_dst保存原始目的地址。 - 在
sockops程序中,将当前 sock 和四元组保存在sock_pair_map中。同时,将四元组信息和对应的原始目的地址写入pair_original_dst中 (之所以不用 cookie,是因为get_sockopt函数无法获取当前 cookie)。 - Envoy 收到连接之后会调用
getsockopt获取当前连接的目的地址,get_sockopt函数会根据四元组信息从pair_original_dst取出原始目的地址并返回,由此完全建立连接。 - 在发送数据阶段,
redir程序会根据四元组信息,从sock_pair_map中读取 sock,然后通过bpf_msg_redirect_hash进行直接转发,加速请求。
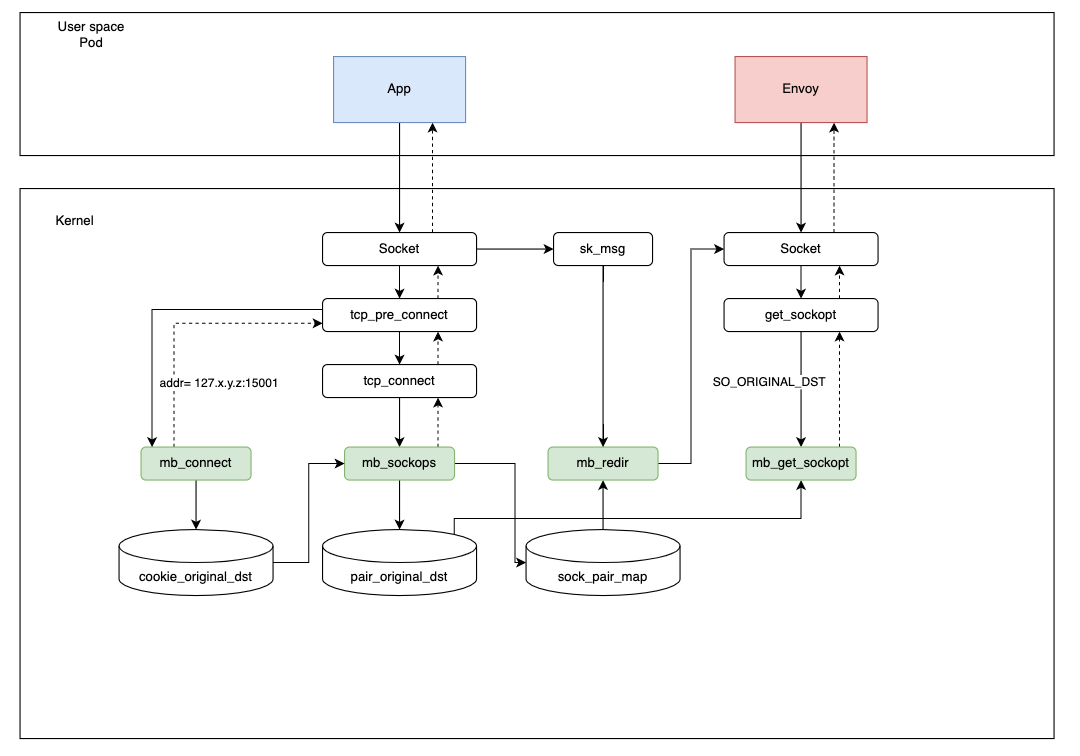
其中,之所以在 connect 时,修改目的地址为 127.x.y.z 而不是 127.0.0.1,是因为在不同的 Pod 中,可能产生冲突的四元组,使用此方式即可巧妙地避开冲突 (每个 Pod 间的目的 IP 不同,不会出现冲突的情况)。
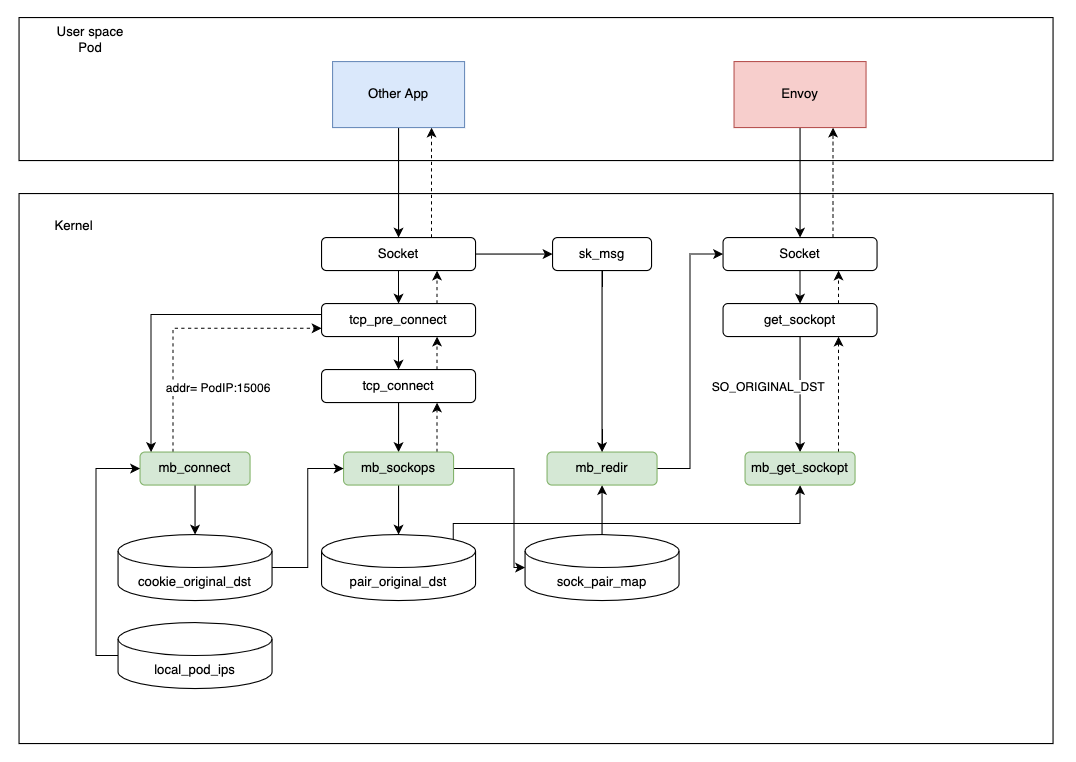
入口流量处理
入口流量处理基本和出口流量类似,唯一的区别是需要将目的地址端口改成 15006。
但是需要注意,由于 eBPF 不像 iptables 能在指定命名空间生效,它是全局的,这就造成如果针对一个本来不是 Istio 管理的 Pod 或者一个外部的 IP 地址,也进行了修改端口的操作,那就会引起严重问题,会让请求无法建立连接。
所以这里设计了一个小的控制平面 (以 DaemonSet 方式部署) Watch 所有的 Pod,类似于 kubelet 那样获取当前节点的 Pod 列表,将已经注入 Sidecar 的 Pod IP 地址写入 local_pod_ips 这个 map。
当处理入站流量时,如果目的地址不在映射中,我们将不会对流量做任何操作。
当我们在做入口流量处理时,如果目的地址不在这个列表之中,就不做处理,让它走原来的逻辑,这样就可以比较灵活且简单地处理入口流量。
其他流程和出口流量流程一样
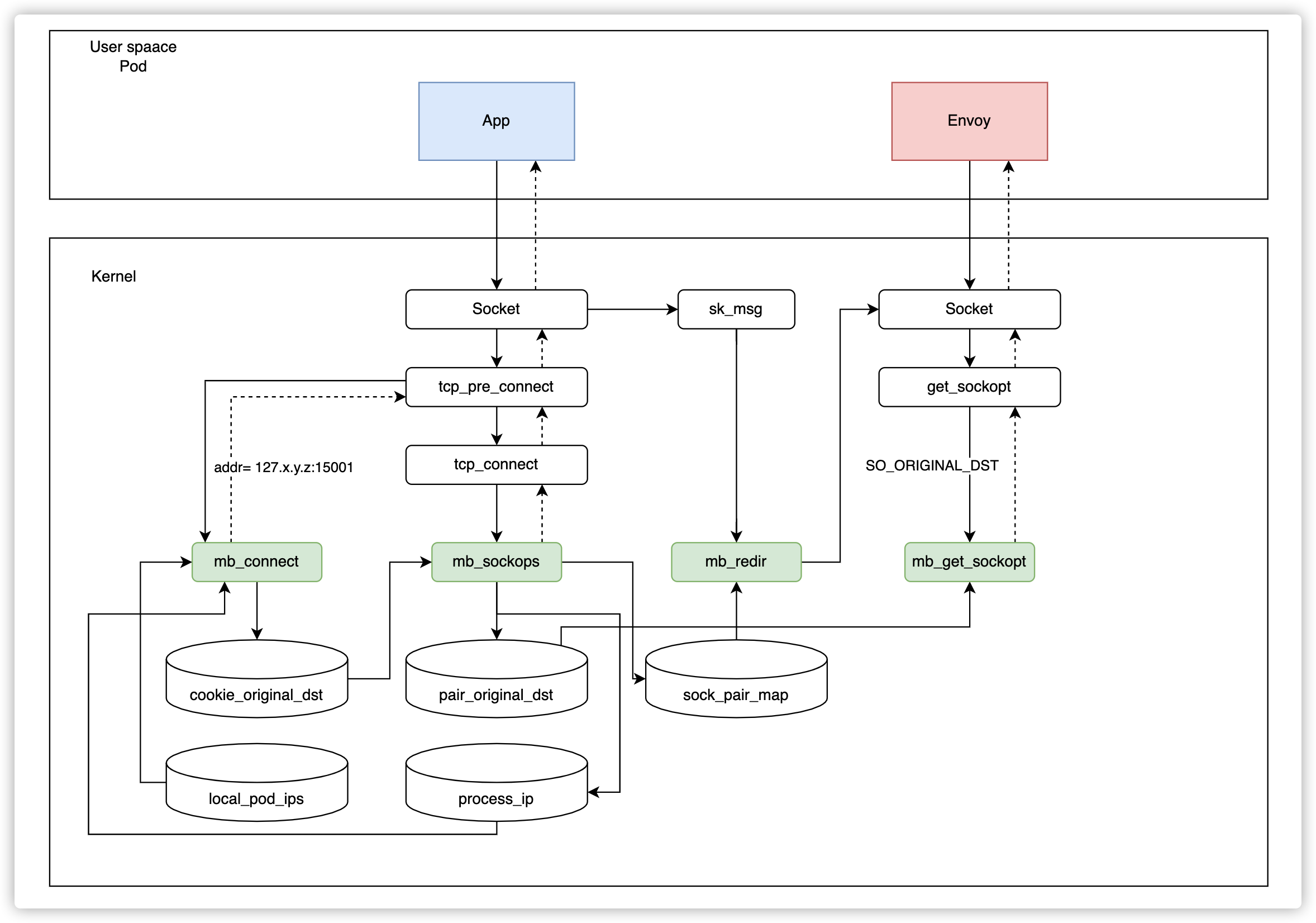
同节点加速
通过入口流量处理,理论上可以直接加速同节点的 Envoy 到 Envoy 速度。但这个场景存在一个问题,Envoy 访问当前 Pod 的应用时会出错。
在 Istio 中,Envoy 访问应用的方式是使用当前 PodIP 加服务端口。经过上述入口流量处理后,我们会发现由于 PodIP 也存在于 local_pod_ips 中,那么这个请求会被转发到 PodIP 的 15006 端口,这显然是不行的,会造成无限递归。
问题来了: 是否有办法可以用 eBPF 获取当前名称空间中的 IP 地址?答案是肯定的!
我们设计了一套反馈机制: 在 Envoy 尝试建立连接时,还是会走重定向到 15006 端口,但是在 sockops 阶段会判断源 IP 和目的地址 IP 是否一致。如果一致,代表发送了错误的请求,那么我们会在 sockops 丢弃这个连接,并将当前的 ProcessID 和 IP 地址信息写入 process_ip 这个 map,让 eBPF 支持进程与 IP 的对应关系。
当下次发送请求时,直接从 process_ip 表检查目的地址是否与当前 IP 地址一致。
连接关系
在使用 Merbridge 应用 eBPF 之前,Pod 到 Pod 间的访问如下:
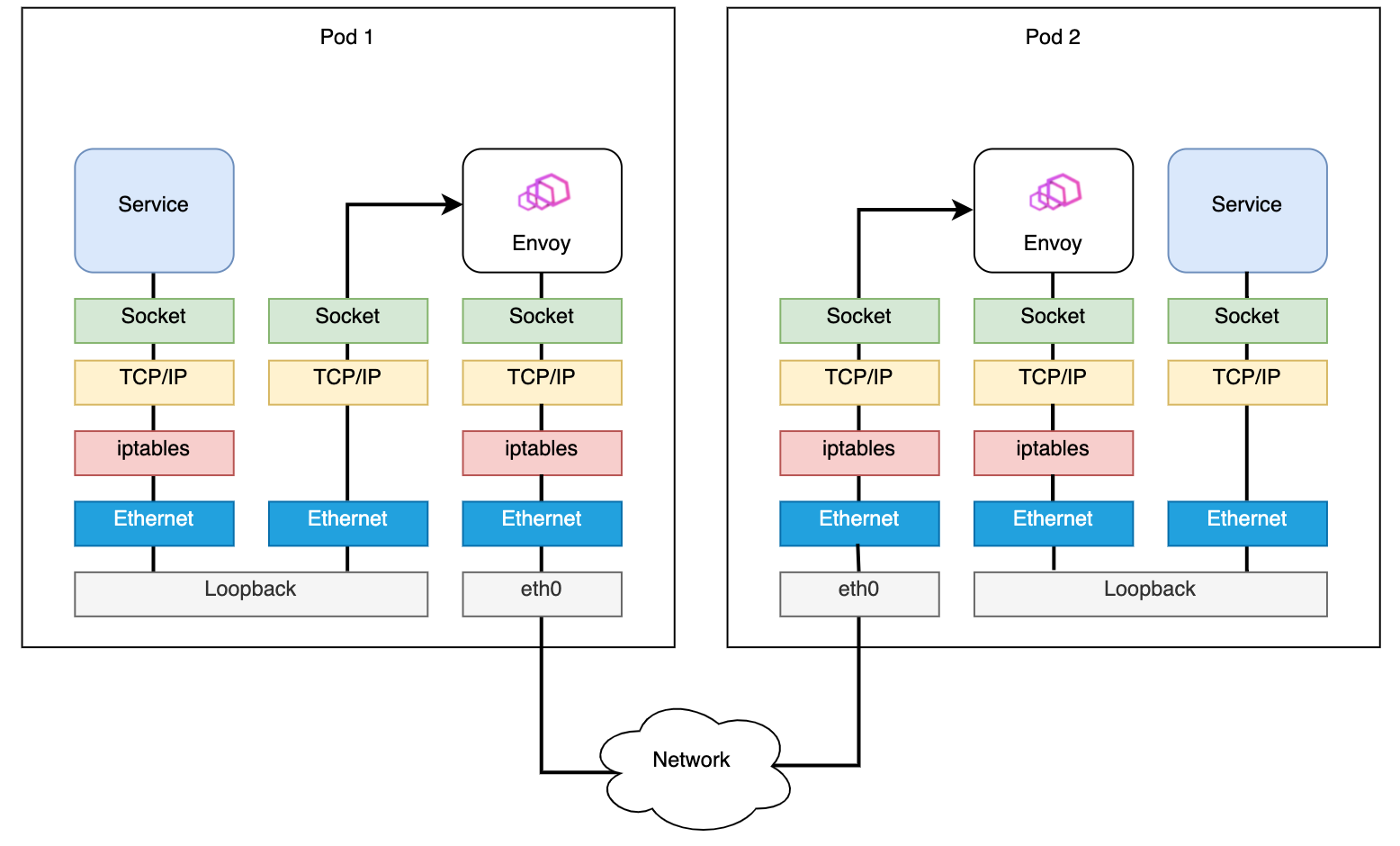
应用 Merbridge 后,出站流量会跳过许多过滤步骤来提高性能:
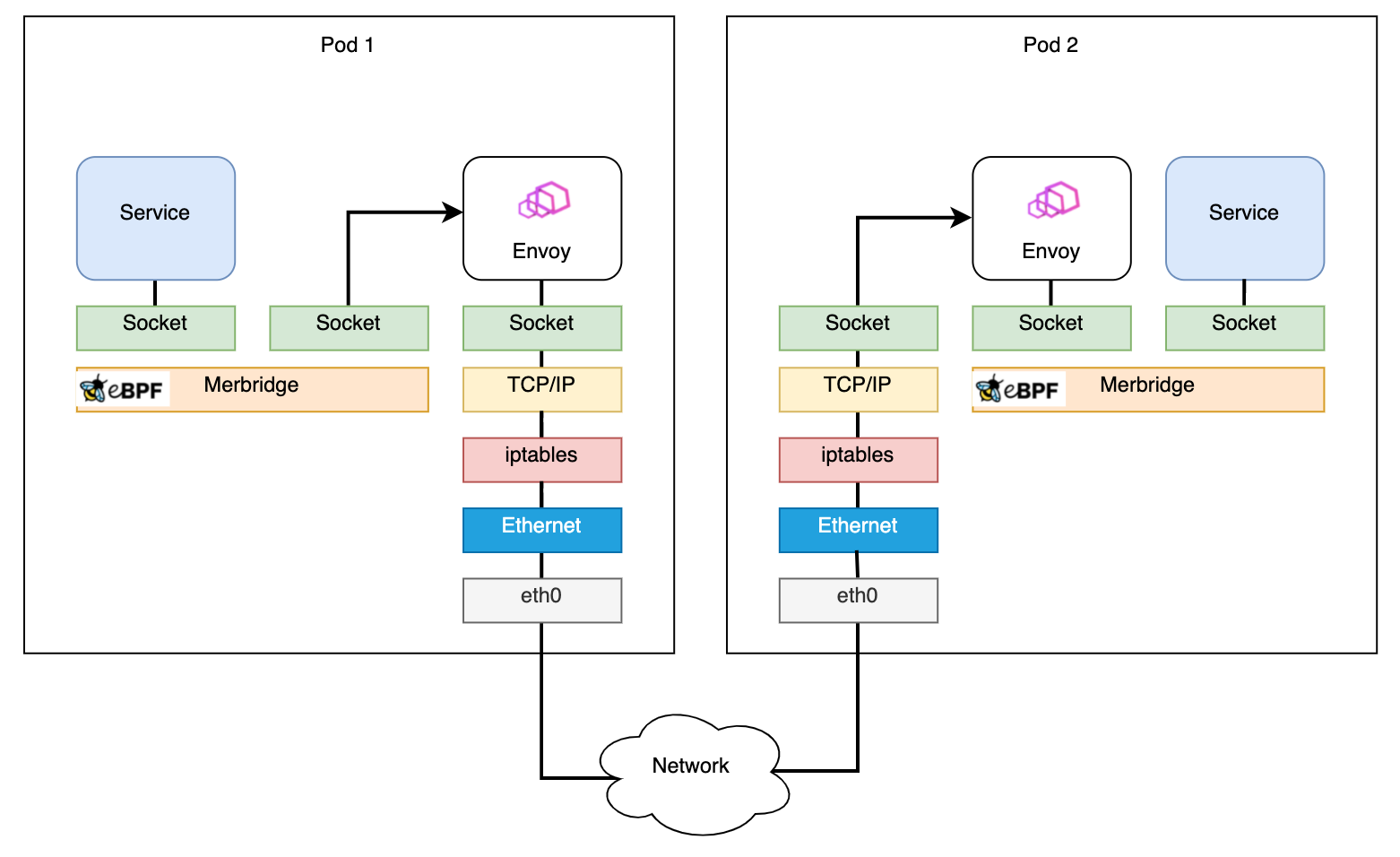
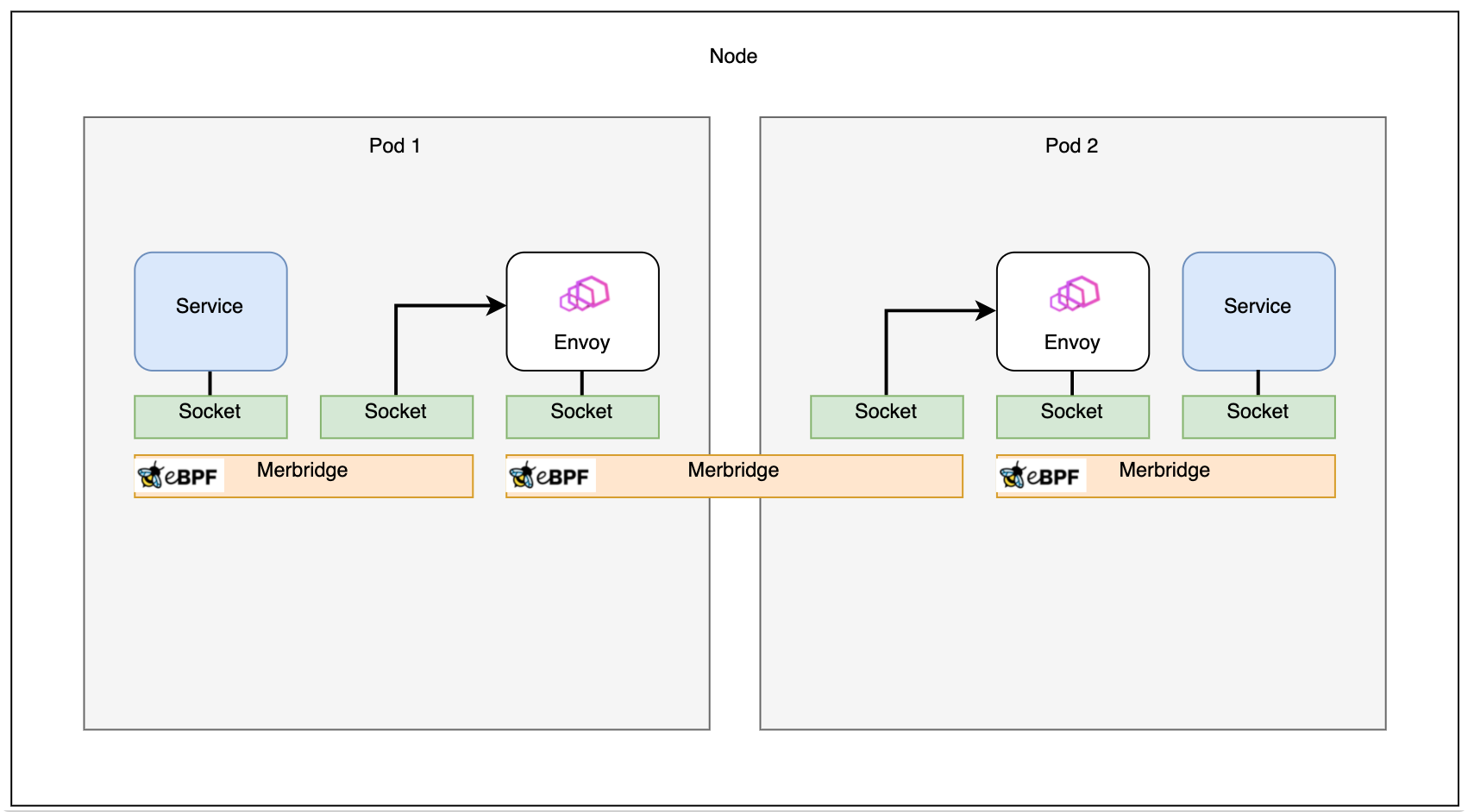
如果两个pod在同一台机器上,通讯将更加高效:
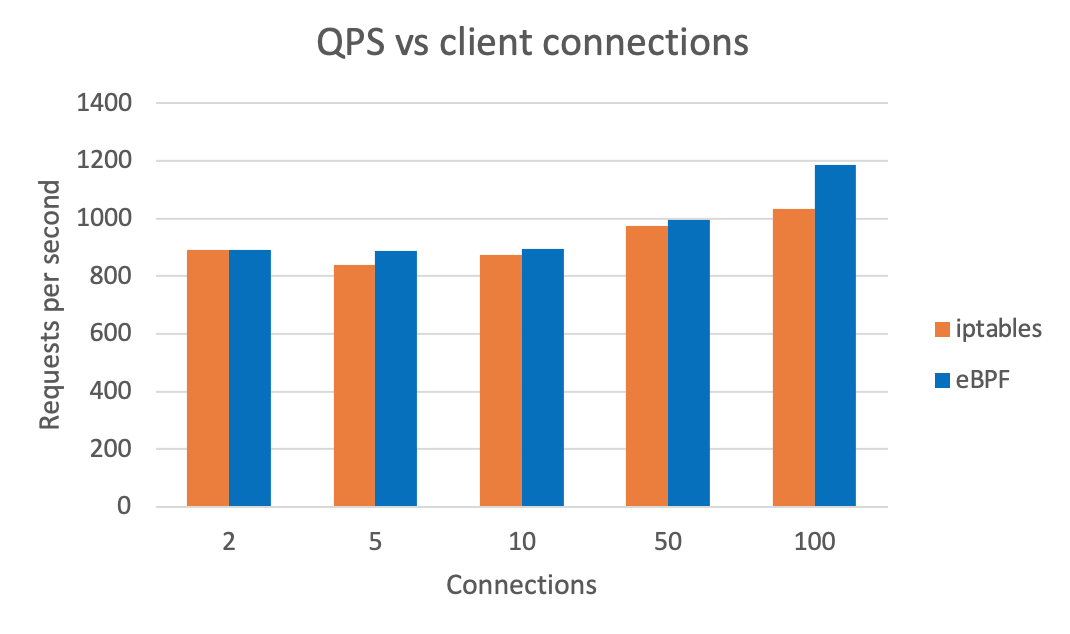
性能结果
使用 eBPF 代替 iptables 对总体延迟的影响(越低越好):

我们还可以看到使用 eBPF 后的整体 QPS(越高越好)。测试结果由 wrk 测试得出。
总结
我们在这篇文章中介绍了 Merbridge 的核心思想。通过使用 eBPF 代替 iptables,可以在服务网格场景下,完全无感知地对流量通路进行加速。同时,不会对现有的 Istio 做任何修改,原有的逻辑依然畅通。这意味着,如果以后不再使用 eBPF,那么可以直接删除掉 DaemonSet,改为传统的 iptables 方式后,也不会出现任何问题。
Merbridge 是一个完全独立的开源项目。它仍处于早期阶段,我们期待有更多的用户和开发者参与进来。如果你能尝试这种新技术来加速你的网格,并给我们一些反馈,我们将不胜感激!
另请参阅
- Merbridge on GitHub
- 使用 eBPF 代替 iptables 优化业务网格数据平面的性能 by Liu Xu, Tencent
- 详细阐述了 Istio 中的 Sidecar 注入和透明流量劫持过程 by Jimmy Song, Tetrate
- 使用 eBPF 加速 Istio 数据平面 by Yizhou Xu, Intel
- 特使的原始目的地过滤器


