Observabilidad
Istio genera telemetría detallada para todas las comunicaciones de servicios dentro de un mesh. Esta telemetría proporciona observabilidad del comportamiento del servicio, lo que permite a los operadores solucionar problemas, mantener y optimizar sus aplicaciones, sin imponer ninguna carga adicional a los desarrolladores de servicios. A través de Istio, los operadores obtienen una comprensión profunda de cómo interactúan los servicios monitoreados, tanto con otros servicios como con los propios componentes de Istio.
Istio genera los siguientes tipos de telemetría para proporcionar observabilidad general de la service mesh:
- Métricas. Istio genera un conjunto de métricas de servicio basadas en las cuatro “señales doradas” de monitoreo (latencia, tráfico, errores y saturación). Istio también proporciona métricas detalladas para el control plane de la mesh. También se proporciona un conjunto predeterminado de paneles de monitoreo de mesh creados sobre estas métricas.
- Trazas distribuidas. Istio genera tramos de traza distribuidos para cada servicio, lo que proporciona a los operadores una comprensión detallada de los flujos de llamadas y las dependencias de los servicios dentro de un mesh.
- Registros de acceso. A medida que el tráfico fluye hacia un servicio dentro de un mesh, Istio puede generar un registro completo de cada solicitud, incluidos los metadatos de origen y destino. Esta información permite a los operadores auditar el comportamiento del servicio hasta el nivel de workload instance individual.
Métricas
Las métricas proporcionan una forma de monitorear y comprender el comportamiento en conjunto.
Para monitorear el comportamiento del servicio, Istio genera métricas para todo el tráfico del servicio dentro, fuera y dentro de una service mesh de Istio. Estas métricas proporcionan información sobre comportamientos como el volumen general de tráfico, las tasas de error dentro del tráfico y los tiempos de respuesta para las solicitudes.
Además de monitorear el comportamiento de los services dentro de un mesh, también es importante monitorear el comportamiento de la mesh misma. Los componentes de Istio exportan métricas sobre sus propios comportamientos internos para proporcionar información sobre la salud y el funcionamiento del control plane de la mesh.
Métricas a nivel de proxy
La recopilación de métricas de Istio comienza con los proxies sidecar (Envoy). Cada proxy genera un amplio conjunto de métricas sobre todo el tráfico que pasa a través del proxy (tanto de entrada como de salida). Los proxies también proporcionan estadísticas detalladas sobre las funciones administrativas del propio proxy, incluida la información de configuración y salud.
Las métricas generadas por Envoy proporcionan un monitoreo de la mesh con la granularidad de los recursos de Envoy (como listeners y clusters). Como resultado, se requiere comprender la conexión entre los services de la mesh y los recursos de Envoy para monitorear las métricas de Envoy.
Istio permite a los operadores seleccionar cuáles de las métricas de Envoy se generan y recopilan en cada workload instance. De forma predeterminada, Istio habilita solo un pequeño subconjunto de las estadísticas generadas por Envoy para evitar sobrecargar los backends de métricas y reducir la sobrecarga de CPU asociada con la recopilación de métricas. Sin embargo, los operadores pueden ampliar fácilmente el conjunto de métricas de proxy recopiladas cuando sea necesario. Esto permite la depuración dirigida del comportamiento de la red, al tiempo que reduce el costo general del monitoreo en toda la mesh.
El sitio de documentación de Envoy incluye una descripción detallada de la recopilación de estadísticas de Envoy. La guía de operaciones sobre Estadísticas de Envoy proporciona más información sobre cómo controlar la generación de métricas a nivel de proxy.
Métricas de ejemplo a nivel de proxy:
envoy_cluster_internal_upstream_rq{response_code_class="2xx",cluster_name="xds-grpc"} 7163
envoy_cluster_upstream_rq_completed{cluster_name="xds-grpc"} 7164
envoy_cluster_ssl_connection_error{cluster_name="xds-grpc"} 0
envoy_cluster_lb_subsets_removed{cluster_name="xds-grpc"} 0
envoy_cluster_internal_upstream_rq{response_code="503",cluster_name="xds-grpc"} 1Métricas a nivel de servicio
Además de las métricas a nivel de proxy, Istio proporciona un conjunto de métricas orientadas al servicio para monitorear las comunicaciones del servicio. Estas métricas cubren las cuatro necesidades básicas de monitoreo de servicios: latencia, tráfico, errores y saturación. Istio se envía con un conjunto predeterminado de paneles para monitorear los comportamientos del servicio basados en estas métricas.
Las métricas estándar de Istio se exportan a Prometheus de forma predeterminada.
El uso de las métricas a nivel de servicio es totalmente opcional. Los operadores pueden optar por desactivar la generación y recopilación de estas métricas para satisfacer sus necesidades individuales.
Métrica de ejemplo a nivel de servicio:
istio_requests_total{
connection_security_policy="mutual_tls",
destination_app="details",
destination_canonical_service="details",
destination_canonical_revision="v1",
destination_principal="cluster.local/ns/default/sa/default",
destination_service="details.default.svc.cluster.local",
destination_service_name="details",
destination_service_namespace="default",
destination_version="v1",
destination_workload="details-v1",
destination_workload_namespace="default",
reporter="destination",
request_protocol="http",
response_code="200",
response_flags="-",
source_app="productpage",
source_canonical_service="productpage",
source_canonical_revision="v1",
source_principal="cluster.local/ns/default/sa/default",
source_version="v1",
source_workload="productpage-v1",
source_workload_namespace="default"
} 214Métricas del control plane
El control plane de Istio también proporciona una colección de métricas de autocontrol. Estas métricas permiten monitorear el comportamiento de Istio mismo (a diferencia del de los services dentro de la mesh).
Para obtener más información sobre qué métricas se mantienen, consulte la documentación de referencia.
Trazas distribuidas
El trazado distribuido proporciona una forma de monitorear y comprender el comportamiento al monitorear solicitudes individuales a medida que fluyen a través de un mesh. Las trazas permiten a los operadores de la mesh comprender las dependencias del servicio y las fuentes de latencia dentro de su service mesh.
Istio admite el trazado distribuido a través de los proxies de Envoy. Los proxies generan automáticamente tramos de traza en nombre de las aplicaciones que representan, requiriendo solo que las aplicaciones reenvíen el contexto de solicitud apropiado.
Istio admite una serie de backends de trazado, incluidos Zipkin, Jaeger y muchas herramientas y servicios que admiten OpenTelemetry. Los operadores controlan la frecuencia de muestreo para la generación de trazas (es decir, la frecuencia con la que se generan los datos de trazado por solicitud). Esto permite a los operadores controlar la cantidad y la velocidad de los datos de trazado que se producen para su malla.
Se puede encontrar más información sobre el trazado distribuido con Istio en nuestras Preguntas frecuentes sobre el trazado distribuido.
Traza distribuida generada por Istio de ejemplo para una sola solicitud:
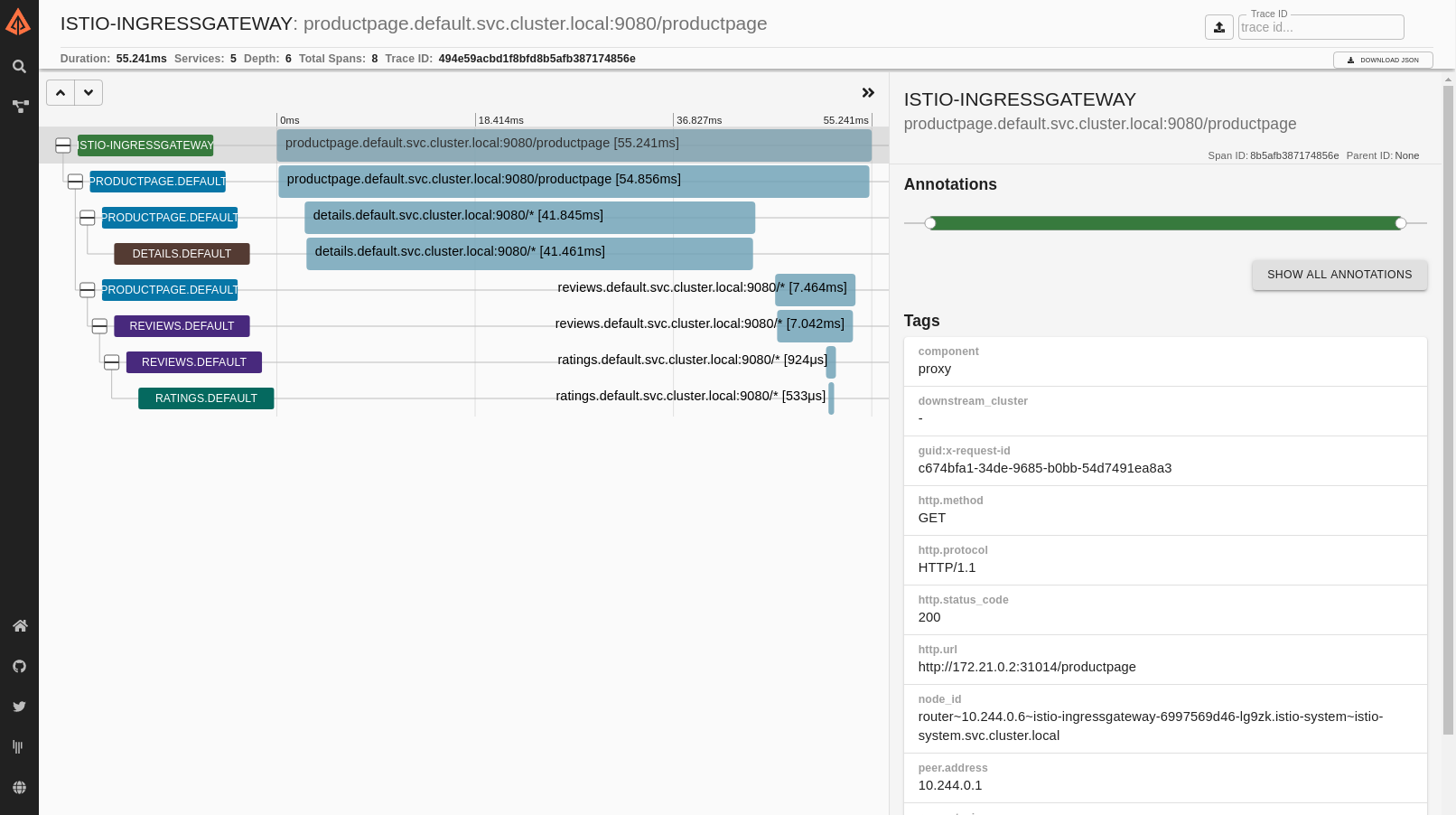
Registros de acceso
Los registros de acceso proporcionan una forma de monitorear y comprender el comportamiento desde la perspectiva de una workload instance individual.
Istio puede generar registros de acceso para el tráfico de servicios en un conjunto configurable de formatos, lo que brinda a los operadores un control total sobre cómo, qué, cuándo y dónde se registra. Para obtener más información, consulte Obtención de los registros de acceso de Envoy.
Registro de acceso de Istio de ejemplo:
[2019-03-06T09:31:27.360Z] "GET /status/418 HTTP/1.1" 418 - "-" 0 135 5 2 "-" "curl/7.60.0" "d209e46f-9ed5-9b61-bbdd-43e22662702a" "httpbin:8000" "127.0.0.1:80" inbound|8000|http|httpbin.default.svc.cluster.local - 172.30.146.73:80 172.30.146.82:38618 outbound_.8000_._.httpbin.default.svc.cluster.local