Secure Application Communications with Mutual TLS and Istio
Dive into securing application communications, mTLS and Istio to achieve end-to-end mTLS among your applications.
One of the biggest reasons users adopt service mesh is to enable secure communication among applications using mutual TLS (mTLS) based on cryptographically verifiable identities. In this blog, we’ll discuss the requirements of secure communication among applications, how mTLS enables and meets all those requirements, along with simple steps to get you started with enabling mTLS among your applications using Istio.
What do you need to secure the communications among your applications?
Modern cloud native applications are frequently distributed across multiple Kubernetes clusters or virtual machines. New versions are being staged frequently and they can rapidly scale up and down based on user requests. As modern applications gain resource utilization efficiency by not being dependent on co-location, it is paramount to be able to apply access policy to and secure the communications among these distributed applications due to increased multiple entry points resulting in a larger attack surface. To ignore this is to invite massive business risk from data loss, data theft, forged data, or simple mishandling.
The following are the common key requirements for secure communications between applications:
Identities
Identity is a fundamental component of any security architecture. Before your applications can send their data securely, identities must be established for the applications. This establishing an identity process is called identity validation - it involves some well-known, trusted authority performing one or more checks on the application workload to establish that it is what it claims to be. Once the authority is satisfied, it grants the workload an identity.
Consider the act of being issued a passport - you will request one from some authority, that authority will probably ask you for several different identity validations that prove you are who you say you are - a birth certificate, current address, medical records, etc. Once you have satisfied all the identity validations, you will (hopefully) be granted the identity document. You can give that identity document to someone else as proof that you have satisfied all the identity validation requirements of the issuing authority, and if they trust the issuing authority (and the identity document itself), they can trust what it says about you (or they can contact the trusted authority and verify the document).
An identity could take any form, but, as with any form of identity document, the weaker the identity validations are, the easier it is to forge, and the less useful that identity document is to anyone using it to make a decision. That’s why, in computing, cryptographically verifiable identities are so important - they are signed by a verifiable authority, similar to your passport and driver’s license. Identities based around anything less are a security weakness that is relatively easy to exploit.
Your system may have identities derived from network properties such as IP addresses with distributed identity caches that track the mapping between identities and these network properties. These identities don’t have strong guarantees as cryptographically verifiable identities because IP addresses could be re-allocated to different workloads and identity caches may not always be updated to the latest.
Using cryptographically verifiable identities for your applications is desired, because exchanging cryptographically verifiable identities for applications during connection establishment is inherently more reliable and secure than systems dependent on mapping IP addresses to identities. These systems depend on distributed identity caches with eventual consistency and staleness issues which could create a structural weakness in Kubernetes, where high rates of automated pod churn are the norm.
Confidentiality
Encrypting the data transmitted among applications is critical - because in a world where breaches are common, costly, and effectively trivial, relying entirely on secure internal environments or other security perimeters has long since ceased to be adequate. To prevent a man-in-the-middle attack, you require a unique encryption channel for a source-destination pair because you want a strong identity uniqueness guarantee to avoid confused deputy problems. In other words, it is not enough to simply encrypt the channel - it must be encrypted using unique keys directly derived from the unique source and destination identities so that only the source and destination can decrypt the data. Further, you may need to customize the encryption, e.g. by choosing specific ciphers, in accordance with what your security team requires.
Integrity
The encrypted data sent over the network from source to destination can’t be modified by any identities other than the source and destination once it is sent. In other words, data received is the same as data sent. If you don’t have data integrity, someone in the middle could modify some bits or the entire content of the data during the communication between the source and destination.
Access Policy Enforcement
Application owners need to apply access policies to their applications and have them enforced
properly, consistently, and unambiguously. In order to apply policy for both ends of a communication
channel, we need an application identity for each end. Once we have a cryptographically verifiable
identity with an unambiguous provenance chain for both ends of a potential communication channel, we
can begin to apply policies about who can communicate with what. Standard TLS, the widely used
cryptographic protocol that secures communication between clients (e.g., web browsers) and servers
(e.g., web servers), only really verifies and mandates an identity for one side - the server. But
for comprehensive end-to-end policy enforcement, it is critical to have a reliable, verifiable,
unambiguous identity for both sides - client and server. This is a common requirement for internal
applications - imagine for example a scenario where only a frontend application should call the
GET method for a backend checkout application, but should not be allowed to call the POST or
DELETE method. Or a scenario where only applications that have a JWT token issued by a particular
JWT issuer can call the GET method for a checkout application. By leveraging cryptographic
identities on both ends, we can ensure powerful access policies are enforced correctly, securely,
and reliably, with a validatable audit trail.
FIPS compliance
Federal Information Processing Standards (FIPS) are standards and guidelines for federal computer systems that are developed by National Institute of Standards and Technology (NIST). Not everyone requires FIPS compliance, but FIPS compliance means meeting all the necessary security requirements established by the U.S. government for protecting sensitive information. It is required when working with the federal government. To follow the guidelines developed by the U.S. government relating to cybersecurity, many in the private sector voluntarily use these FIPS standards.
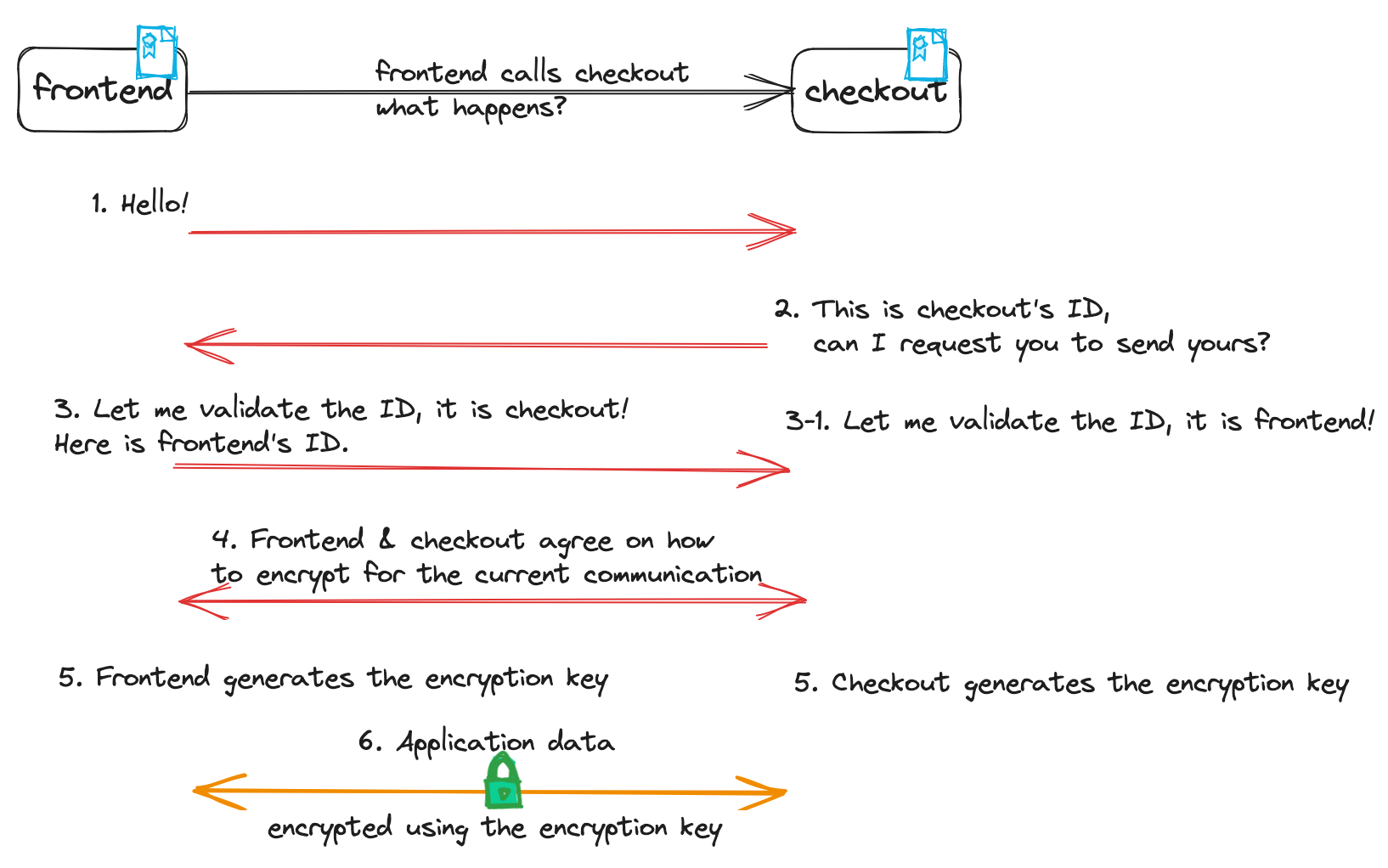
To illustrate the above secure application requirements (identity, confidentiality and integrity),
let’s use the example that the frontend application calls the checkout application. Remember, you can think of ID in the diagram as any kind of identity document such as a government issued passport,
photo identifier:
How does mTLS satisfy the above requirements?
TLS 1.3 (the most recent TLS version at the time of writing) specification’s primary goal is to provide a secure channel between two communicating peers. The TLS secure channel has the following properties:
- Authentication: the server side of the channel is always authenticated, the client side is optionally authenticated. When the client is also authenticated, the secure channel becomes a mutual TLS channel.
- Confidentiality: Data is encrypted and only visible to the client and server. Data must be encrypted using keys that are unambiguously cryptographically bound to the source and destination identity documents in order to reliably protect the application-layer traffic.
- Integrity: data sent over the channel can’t be modified without detection. This is guaranteed by the fact that only source and destination have the key to encrypt and decrypt the data for a given session.
mTLS internals
We’ve established that cryptographically verifiable identities are key for securing channels and supporting access policy enforcement, and we’ve established that mTLS is a battle-tested protocol that mandates some extremely important guarantees for using cryptographically verifiable identities on both ends of a channel - let’s get into some detail on how the mTLS protocol actually works under the hood.
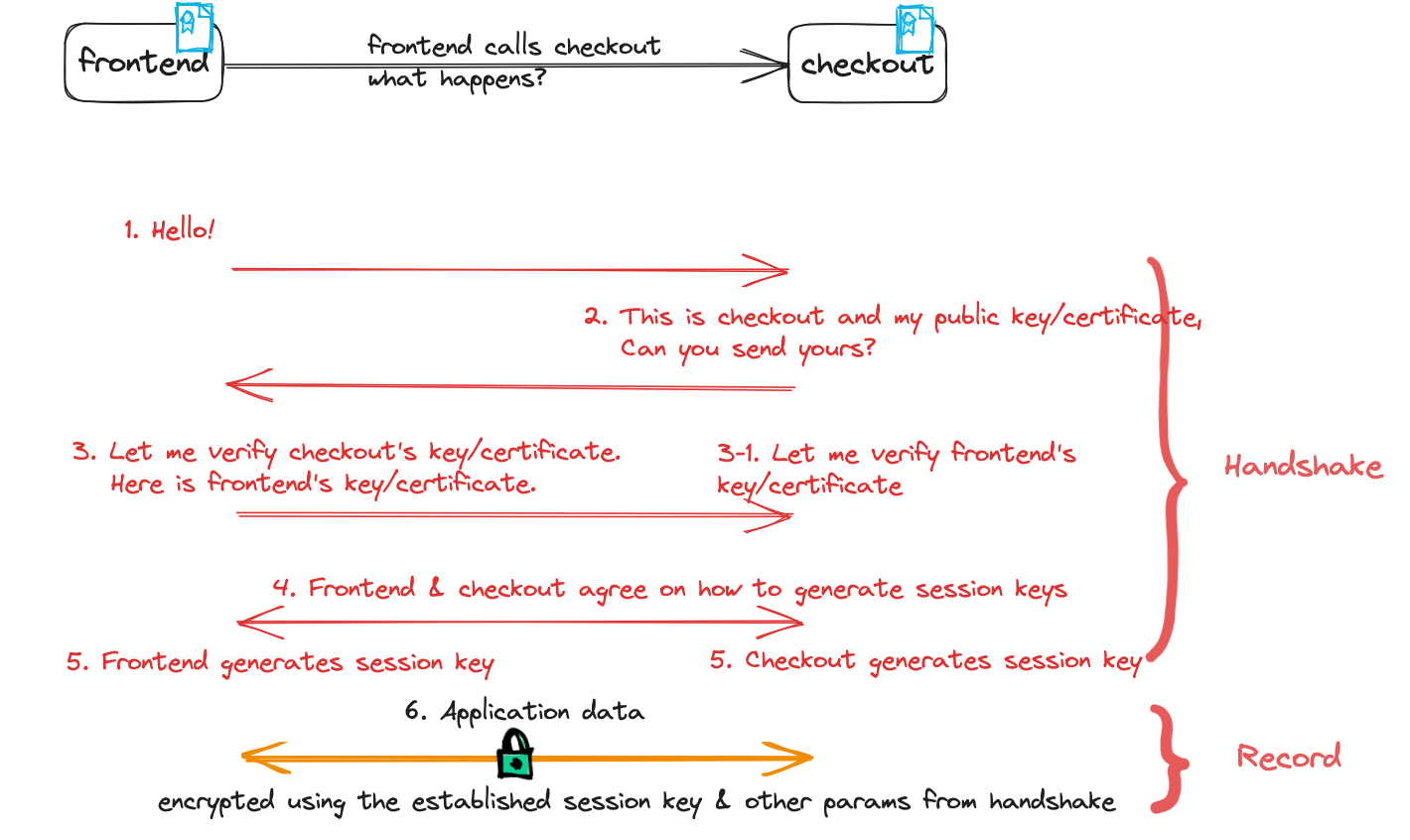
Handshake protocol
The handshake protocol authenticates the communicating peers, negotiates cryptographic modes and parameters, and establishes shared keying material. In other words, the role of the handshake is to verify the communicating peers’ identities and negotiate a session key, so that the rest of the connection can be encrypted based on the session key. When your applications make a mTLS connection, server and client negotiate a cipher suite, which dictates what encryption algorithm your applications will use for the rest of the connection and your applications also negotiate the cryptographic session key to use. The whole handshake is designed to resist tampering - interference by any entities that do not possess the same unique, cryptographically verifiable identity document as the source and/or destination will be rejected. For this reason, it is important to check the whole handshake and verify its integrity before any communicating peer continues with the application data.
The handshake can be thought of as having three phases per the
handshake protocol overview in the TLS 1.3
specification - again, let’s use the example of a frontend application calling a backend
checkout application:
- Phase 1:
frontendandcheckoutnegotiates the cryptographic parameters and encryption keys that can be used to protect the rest of the handshake and traffic data. - Phase 2: everything in this phase and after are encrypted. In this phase,
frontendandcheckoutestablish other handshake parameters, and whether or not the client is also authenticated - that is, mTLS. - Phase 3:
frontendauthenticatescheckoutvia its cryptographically verifiable identity (and, in mTLS,checkoutauthenticatesfrontendin the same way).
There are a few major differences since TLS 1.2 related to handshake, refer to the TLS 1.3 specification for more details:
- All handshake messages (phase 2 and 3) are encrypted using the encryption keys negotiated in phase 1.
- Legacy symmetric encryption algorithms have been pruned.
- A zero round-trip time (0-RTT) mode was added, saving a round trip at connection setup.
Record protocol
Having negotiated the TLS protocol version, session-key & HMAC during the handshake phase, the peers can now securely exchange encrypted data that is chunked by the record protocol. It is critical (and required as part of the spec) to use the exact same negotiated parameters from the handshake to encrypt the traffic to ensure the traffic confidentiality and integrity.
Putting the two protocols from the TLS 1.3 specification together and using the frontend and
checkout applications to illustrate the flow as below:
Who issues the identity certificates for frontend and checkout? They are commonly issued by a
certificate authority (CA) which either has
its own root certificate or uses an intermediate
certificate from its root CA. A root certificate is basically a public key certificate that
identifies a root CA, which you likely already have in your organization. The root certificate is
distributed to frontend (or checkout) in addition to its own root-signed identity certificate. This is how
everyday, basic Public Key Infrastructure (PKI) works - a CA has responsibility for validating an
entity’s identity document, and then grants it an unforgeable identity document in the form of a
certificate.
You can rely on your CA and intermediate CAs as source of identity truth in a structural fashion
that maintains high availability and stable, persistently-verifiable identity guarantees in a way
that a massive distributed cache of IP and identity maps simply cannot. When the frontend and
checkout identity certificates are issued by the same root certificate, frontend and checkout
can verify their peer identities consistently and reliably regardless of which cluster or nodes or scale
they run.
You learned about how mTLS provides cryptographic identity, confidentiality and integrity, what about scalability as you grow to thousands or more applications among multiple clusters? If you establish a single root certificate across multiple clusters, the system doesn’t need to care when your application gets a connection request from another cluster as long as it is trusted by the root certificate - the system knows the identity on the connection is cryptographically verified. As your application pod changes IP or is redeployed to a different cluster or network, your application (or component acting on behalf of it) simply originates the traffic with its trusted certificate minted by the CA to the destination. It can be 500+ network hops or can be direct; your access policies for your application are enforced in the same fashion regardless of the topology, without needing to keep track of the identity cache and calculate which IP address maps to which application pod.
What about FIPS compliance? Per TLS 1.3 specification, TLS-compliant applications must implement the
TLS_AES_128_GCM_SHA256 cipher suite, and are recommended to implement TLS_AES_256_GCM_SHA384, both
of which are also in the guidelines for TLS
by NIST. RSA or ECDSA server certificates are also recommended by both TLS 1.3 specification and
NIST’s guideline for TLS. As long as you use mTLS and FIPS 140-2 or 140-3 compliant cryptographic
modules for your mTLS connections, you will be on the right path for
FIPS 140-2 or 140-3 validation.
What could go wrong
It is critical to implement mTLS exactly as the TLS 1.3 specification dictates. Without using proper mTLS following the TLS specification, here are a few things that can go wrong without detection:
What if someone in the middle of the connection silently captures the encrypted data?
If the connection doesn’t follow exactly the handshake and record protocols as outlined in the TLS specification, for example, the connection follows the handshake protocol but not using the negotiated session key and parameters from the handshake in the record protocol, you may have your connection’s handshake unrelated to the record protocol where identities could be different between the handshake and record protocols. TLS requires that the handshake and record protocols share the same connection because separating them increases the attack surface for man-in-the-middle attacks.
A mTLS connection has a consistent end-to-end security from start of the handshake to finish. The encrypted data is encrypted with the session key negotiated using the public key in the certificate. Only the source and destination can decrypt the data with the private key. In other words, only the owner of the certificate who has the private key can decrypt the data. Unless a hacker has control of the private key of the certificate, he or she doesn’t have a way to mess around with the mTLS connection to successfully execute a man-in-the-middle attack.
What if either source or destination identity is not cryptographically secure?
If the identity is based on network properties such as IP address, which could be re-allocated to other pods, the identity can’t be validated using cryptographic techniques. Since this type of identity isn’t based on cryptographic identity, your system likely has an identity cache to track the mapping between the identity, the pod’s network labels, the corresponding IP address and the Kubernetes node info where the pod is deployed. With an identity cache, you could run into pod IP addresses being reused and identity mistaken where policy isn’t enforced properly when the identity cache gets out of sync for a short period of time. For example, if you don’t have cryptographic identity on the connection between the peers, your system would have to get the identity from the identity cache which could be outdated or incomplete.
These identity caches that map identity to workload IPs are not ACID (Atomicity, Consistency, Isolation, and Durability) and you want your security system to be applied to something with strong guarantees. Consider the following properties and questions you may want to ask yourself:
- Staleness: How can a peer verify that an entry in the cache is current?
- Incompleteness: If there’s a cache miss and the system fails to close the connection, does the network become unstable when it’s only the cache synchronizer that is failing?
- What if something simply doesn’t have an IP? For example, an AWS Lambda service doesn’t by default have a public IP.
- Non-transactional: If you read the identity twice will you see the same value? If you are not careful in your access policy or auditing implementation this can cause real issues.
- Who will guard the guards themselves? Are there established practices to protect the cache like a CA has? What proof do you have that the cache has not been tampered with? Are you forced to reason about (and audit) the security of some complex infrastructure that is not your CA?
Some of the above are worse than others. You can apply the failing closed principle but that does not solve all of the above.
Identities are also used in enforcing access policies such as authorization policy, and these
access policies are in the request path where your system has to make decisions fast to allow or
deny the access. Whenever identities become mistaken, access policies could be bypassed without
being detected or audited. For example, your identity cache may have your checkout pod’s prior
allocated IP address associated as one of the checkout identities. If the checkout pod gets
recycled and the same IP address is just allocated to one of the frontend pods, that frontend pod could have the checkout’s identity before the cache is updated, which could cause wrong access
policies to be enforced.
Let us illustrate the identity cache staleness problem assuming the following large scale multi-cluster deployment:
- 100 clusters where each cluster has 100 nodes with 20 pods per node. The number of total pods is 200,000.
- 0.25% of pods are being churned at all times (rollout, restarts, recovery, node churn, …), each churn is a 10 second window.
- 500 pods which are being churned are distributed to 10,000 nodes (caches) every 10 secs
- If the cache synchronizer stalls what % stale is the system after 5 minutes - potentially as high as 7.5%!
Above assumes the cache synchronizer is in a steady state. If cache synchronizer has a brown-out it would affect its health-checking which increases churn rate, leading to cascading instability.
CA could also be compromised by an attacker who claims to present someone else and trick the CA to issue a certificate. The attacker can then use that certificate to communicate with other peers. This is where certificate revocation can remediate the situation by revoking the certificate so it is no longer valid. Otherwise the attacker can exploit the compromised certificate till expiry. It is critical to keep the private key for the root certificates in an HSM that is kept offline and use intermediate certificates for signing workload certificates. In the event when CA is brown-out or stalled for 5 minutes, you won’t be able to obtain new or renewed workload certificates but the previously issued and valid certificates continue to provide strong identity guarantees for your workloads. For increased reliability for issuance, you can deploy Intermediate CAs to different zones and regions.
mTLS in Istio
Enable mTLS
Enabling mTLS in Istio for intra-mesh applications is very simple. All you need is to add your applications to the mesh, which can be done by labeling your namespace for either sidecar injection or ambient. In the case of sidecar, a rollout restart would be required for sidecar to be injected to your application pods.
Cryptographic identity
In Kubernetes environment, Istio creates an application’s identity based on its service account. Identity certificate is provided to each application pod in the mesh after you add your application to the mesh.
By default, your pod’s identity certificate expires in 24 hours and Istio rotates the pod identity certificate every 12 hours so that in the event of a compromise (for example, compromised CA or stolen private key for the pod), the compromised certificate only works for a very limited period of time until the certificate expires and therefore limit the damage it can cause.
Enforce strict mTLS
The default mTLS behavior is mTLS whenever possible but not strictly enforced. To strictly enforce your application to accept only mTLS traffic, you can use Istio’s PeerAuthentication policy, mesh-wide or per namespace or workload. In addition, you can also apply Istio’s AuthorizationPolicy to control access for your workloads.
TLS version
TLS version 1.3 is the default in Istio for intra-mesh application communication with the Envoy’s
default cipher suites
(for example TLS_AES_256_GCM_SHA384 for Istio 1.19.0). If you need an older TLS version, you can
configure a different mesh-wide minimum TLS protocol version for your workloads.
Wrapping up
The TLS protocol, as established by the Internet Engineering Task Force (IETF), is one of the most widely-reviewed, expert-approved, battle-tested data security protocols in existence. TLS is also widely used globally - whenever you visit any secured website, you shop with confidence partly because of the padlock icon to indicate that you are securely connected to a trusted site by using TLS. The TLS 1.3 protocol was designed with end-to-end authentication, confidentiality, and integrity to ensure your application’s identity and communications are not compromised, and to prevent man-in-the-middle attacks. In order to achieve that (and to be considered standards-compliant TLS), it is not only important to properly authenticate the communicating peers but also critical to encrypt the traffic using the keys established from the handshake. Now that you know mTLS excels at satisfying your secure application communication requirements (cryptographic identities, confidentiality, integrity and access policy enforcement), you can simply use Istio to upgrade your intra-mesh application communication with mTLS out of the box - with very little configuration!
Huge thanks to Louis Ryan, Ben Leggett, John Howard, Christian Posta, Justin Pettit who contributed significant time in reviewing and proposing updates to the blog!


